This post is co-written with Dean Steel and Simon Gatie from Aviva.
With a presence in 16 countries and serving over 33 million customers, Aviva is a leading insurance company headquartered in London, UK. With a history dating back to 1696, Aviva is one of the oldest and most established financial services organizations in the world. Aviva’s mission is to help people protect what matters most to them—be it their health, home, family, or financial future. To achieve this effectively, Aviva harnesses the power of machine learning (ML) across more than 70 use cases. Previously, ML models at Aviva were developed using a graphical UI-driven tool and deployed manually. This approach led to data scientists spending more than 50% of their time on operational tasks, leaving little room for innovation, and posed challenges in monitoring model performance in production.
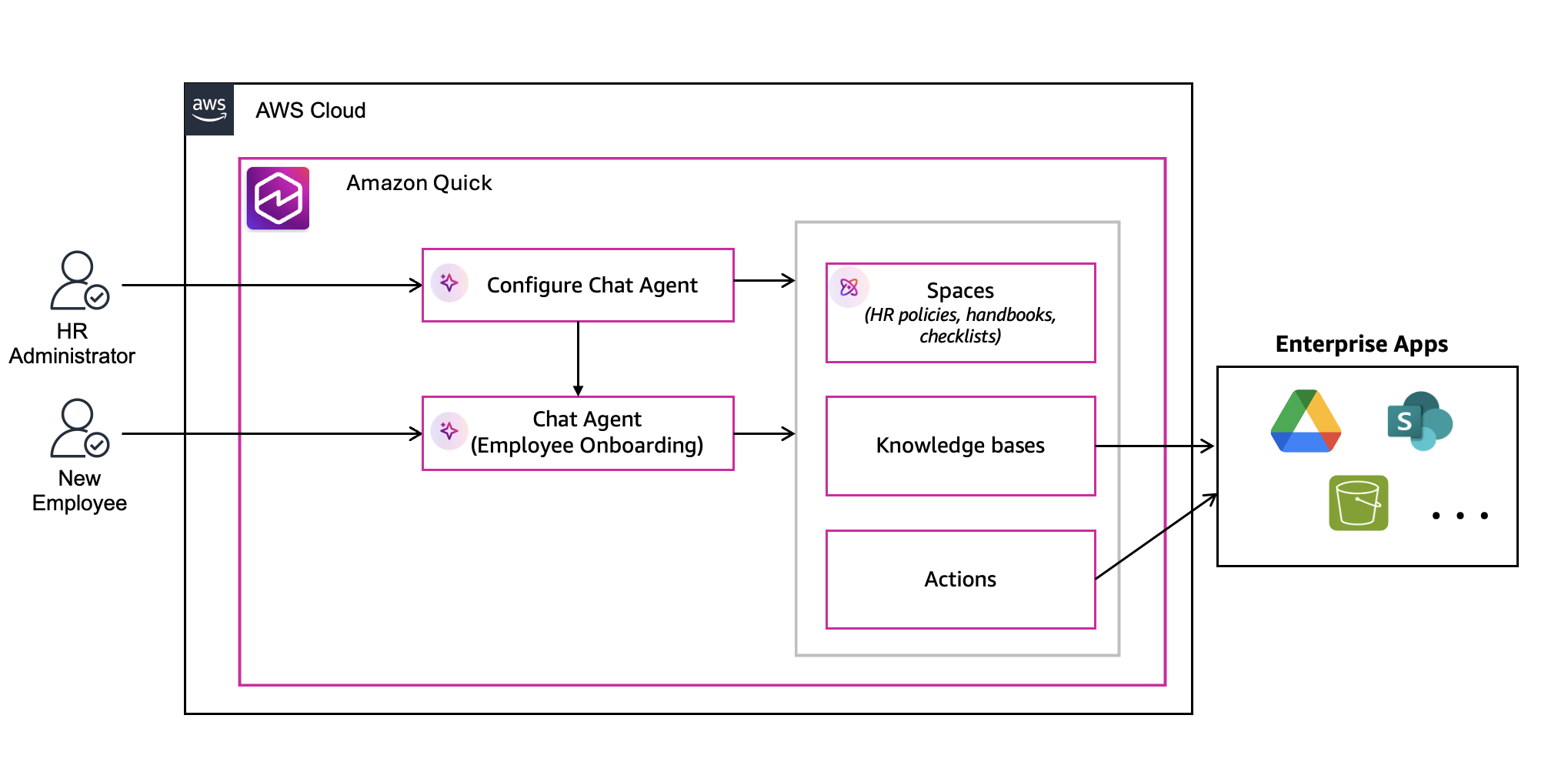
In this post, we describe how Aviva built a fully serverless MLOps platform based on the AWS Enterprise MLOps Framework and Amazon SageMaker to integrate DevOps best practices into the ML lifecycle. This solution establishes MLOps practices to standardize model development, streamline ML model deployment, and provide consistent monitoring. We illustrate the entire setup of the MLOps platform using a real-world use case that Aviva has adopted as its first ML use case.
The Challenge: Deploying and operating ML models at scale
Approximately 47% of ML projects never reach production, according to Gartner. Despite the advancements in open source data science frameworks and cloud services, deploying and operating these models remains a significant challenge for organizations. This struggle highlights the importance of establishing consistent processes, integrating effective monitoring, and investing in the necessary technical and cultural foundations for a successful MLOps implementation.
For companies like Aviva, which handles approximately 400,000 insurance claims annually, with expenditures of about £3 billion in settlements, the pressure to deliver a seamless digital experience to customers is immense. To meet this demand amidst rising claim volumes, Aviva recognizes the need for increased automation through AI technology. Therefore, developing and deploying more ML models is crucial to support their growing workload.
To prove the platform can handle onboarding and industrialization of ML models, Aviva picked their Remedy use case as their first project. This use case concerns a claim management system that employs a data-driven approach to determine whether submitted car insurance claims qualify as either total loss or repair cases, as illustrated in the following diagram
The workflow consists of the following steps:
The workflow begins when a customer experiences a car accident.
The customer contacts Aviva, providing information about the incident and details about the damage.
To determine the estimated cost of repair, 14 ML models and a set of business rules are used to process the request.
The estimated cost is compared with the car’s current market value from external data sources.
Information related to similar cars for sale nearby is included in the analysis.
Based on the processed data, a recommendation is made by the model to either repair or write off the car. This recommendation, along with the supporting data, is provided to the claims handler, and the pipeline reaches its final state.
The successful deployment and evaluation of the Remedy use case on the MLOps platform was intended to serve as a blueprint for future use cases, providing maximum efficiency by using templated solutions.
Solution overview of the MLOps platform
To handle the complexity of operationalizing ML models at scale, AWS offers provides an MLOps offering called AWS Enterprise MLOps Framework, which can be used for a wide variety of use cases. The offering encapsulates a best practices approach to build and manage MLOps platforms based on the consolidated knowledge gained from a multitude of customer engagements carried out by AWS Professional Services in the last five 5 years. The proposed baseline architecture can be logically divided into four building blocks which that are sequentially deployed into the provided AWS accounts, as illustrated in the following diagram below.
The building blocks are as follows:
Networking – A virtual private cloud (VPC), subnets, security groups, and VPC endpoints are deployed across all accounts.
Amazon SageMaker Studio – SageMaker Studio offers a fully integrated ML integrated development environment (IDE) acting as a data science workbench and control panel for all ML workloads.
Amazon SageMaker Projects templates – These ready-made infrastructure sets cover the ML lifecycle, including continuous integration and delivery (CI/CD) pipelines and seed code. You can launch these from SageMaker Studio with a few clicks, either choosing from preexisting templates or creating custom ones.
Seed code – This refers to the data science code tailored for a specific use case, divided between two repositories: training (covering processing, training, and model registration) and inference (related to SageMaker endpoints). The majority of time in developing a use case should be dedicated to modifying this code.
The framework implements the infrastructure deployment from a primary governance account to separate development, staging, and production accounts. Developers can use the AWS Cloud Development Kit (AWS CDK) to customize the solution to align with the company’s specific account setup. In adapting the AWS Enterprise MLOps Framework to a three-account structure, Aviva has designated accounts as follows: development, staging, and production. This structure is depicted in the following architecture diagram. The governance components, which facilitate model promotions with consistent processes across accounts, have been integrated into the development account.
Building reusable ML pipelines
The processing, training, and inference code for the Remedy use case was developed by Aviva’s data science team in SageMaker Studio, a cloud-based environment designed for collaborative work and rapid experimentation. When experimentation is complete, the resulting seed code is pushed to an AWS CodeCommit repository, initiating the CI/CD pipeline for the construction of a SageMaker pipeline. This pipeline comprises a series of interconnected steps for data processing, model training, parameter tuning, model evaluation, and the registration of the generated models in the Amazon SageMaker Model Registry.
Amazon SageMaker Automatic Model Tuning enabled Aviva to utilize advanced tuning strategies and overcome the complexities associated with implementing parallelism and distributed computing. The initial step involved a hyperparameter tuning process (Bayesian optimization), during which approximately 100 model variations were trained (5 steps with 20 models trained concurrently in each step). This feature integrates with Amazon SageMaker Experiments to provide data scientists with insights into the tuning process. The optimal model is then evaluated in terms of accuracy, and if it exceeds a use case-specific threshold, it is registered in the SageMaker Model Registry. A custom approval step was constructed, such that only Aviva’s lead data scientist can permit the deployment of a model through a CI/CD pipeline to a SageMaker real-time inference endpoint in the development environment for further testing and subsequent promotion to the staging and production environment.
Serverless workflow for orchestrating ML model inference
To realize the actual business value of Aviva’s ML model, it was necessary to integrate the inference logic with Aviva’s internal business systems. The inference workflow is responsible for combining the model predictions, external data, and business logic to generate a recommendation for claims handlers. The recommendation is based on three possible outcomes:
Write off a vehicle (expected repairs cost exceeds the value of the vehicle)
Seek a repair (value of the vehicle exceeds repair cost)
Require further investigation given a borderline estimation of the value of damage and the price for a replacement vehicle
The following diagram illustrates the workflow.
The workflow starts with a request to an API endpoint hosted on Amazon API Gateway originating from a claims management system, which invokes an AWS Step Functions workflow that uses AWS Lambda to complete the following steps:
The input data of the REST API request is transformed into encoded features, which is utilized by the ML model.
ML model predictions are generated by feeding the input to the SageMaker real-time inference endpoints. Because Aviva processes daily claims at irregular intervals, real-time inference endpoints help overcome the challenge of providing predictions consistently at low latency.
ML model predictions are further processed by a custom business logic to derive a final decision (of the three aforementioned options).
The final decision, along with the generated data, is consolidated and transmitted back to the claims management system as a REST API response.
Monitor ML model decisions to elevate confidence amongst users
The ability to obtain real-time access to detailed data for each state machine run and task is critically important for effective oversight and enhancement of the system. This includes providing claim handlers with comprehensive details behind decision summaries, such as model outputs, external API calls, and applied business logic, to make sure recommendations are based on accurate and complete information. Snowflake is the preferred data platform, and it receives data from Step Functions state machine runs through Amazon CloudWatch logs. A series of filters screen for data pertinent to the business. This data then transmits to an Amazon Data Firehose delivery stream and subsequently relays to an Amazon Simple Storage Service (Amazon S3) bucket, which is accessed by Snowflake. The data generated by all runs is used by Aviva business analysts to create dashboards and management reports, facilitating insights such as monthly views of total losses by region or average repair costs by vehicle manufacturer and model.
Security
The described solution processes personally identifiable information (PII), making customer data protection the core security focus of the solution. The customer data is protected by employing networking restrictions, because processing is run inside the VPC, where data is logically separated in transit. The data is encrypted in transit between steps of the processing and encrypted at rest using AWS Key Management Service (AWS KMS). Access to the production customer data is restricted on a need-to-know basis, where only the authorized parties are allowed to access production environment where this data resides.
The second security focus of the solution is protecting Aviva’s intellectual property. The code the data scientists and engineers are working on is stored securely in the dev AWS account, private to Aviva, in the CodeCommit git repositories. The training data and the artifacts of the trained models are stored securely in the S3 buckets in the dev account, protected by AWS KMS encryption at rest, with AWS Identity and Access Management (IAM) policies restricting access to the buckets to only the authorized SageMaker endpoints. The code pipelines are private to the account as well, and reside in the customer’s AWS environment.
The auditability of the workflows is provided by logging the steps of inference and decision-making in the CloudWatch logs. The logs are encrypted at rest as well with AWS KMS, and are configured with a lifecycle policy, guaranteeing availability of audit information for the required compliance period. To maintain security of the project and operate it securely, the accounts are enabled with Amazon GuardDuty and AWS Config. AWS CloudTrail is used to monitor the activity within the accounts. The software to monitor for security vulnerabilities resides primarily in the Lambda functions implementing the business workflows. The processing code is primarily written in Python using libraries that are periodically updated.
Conclusion
This post provided an overview of the partnership between Aviva and AWS, which resulted in the construction of a scalable MLOps platform. This platform was developed using the open source AWS Enterprise MLOps Framework, which integrated DevOps best practices into the ML lifecycle. Aviva is now capable of replicating consistent processes and deploying hundreds of ML use cases in weeks rather than months. Furthermore, Aviva has transitioned entirely to a pay-as-you-go model, resulting in a 90% reduction in infrastructure costs compared to the company’s previous on-premises ML platform solution.
Explore the AWS Enterprise MLOps Framework on GitHub and learn more about MLOps on Amazon SageMaker to see how it can accelerate your organization’s MLOps journey.
About the Authors
Dean Steel is a Senior MLOps Engineer at Aviva with a background in Data Science and actuarial work. He is passionate about all forms of AI/ML with experience developing and deploying a diverse range of models for insurance-specific applications, from large transformers through to linear models. With an engineering focus, Dean is a strong advocate of combining AI/ML with DevSecOps in the cloud using AWS. In his spare time, Dean enjoys exploring music technology, restaurants and film.
Simon Gatie, Principle Analytics Domain Authority at Aviva in Norwich brings a diverse background in Physics, Accountancy, IT, and Data Science to his role. He leads Machine Learning projects at Aviva, driving innovation in data science and advanced technologies for financial services.
Gabriel Rodriguez is a Machine Learning Engineer at AWS Professional Services in Zurich. In his current role, he has helped customers achieve their business goals on a variety of ML use cases, ranging from setting up MLOps pipelines to developing a fraud detection application. Whenever he is not working, he enjoys doing physical exercises, listening to podcasts, or traveling.
Marco Geiger is a Machine Learning Engineer at AWS Professional Services based in Zurich. He works with customers from various industries to develop machine learning solutions that use the power of data for achieving business goals and innovate on behalf of the customer. Besides work, Marco is a passionate hiker, mountain biker, football player, and hobby barista.
Andrew Odendaal is a Senior DevOps Consultant at AWS Professional Services based in Dubai. He works across a wide range of customers and industries to bridge the gap between software and operations teams and provides guidance and best practices for senior management when he’s not busy automating something. Outside of work, Andrew is a family man that loves nothing more than a binge-watching marathon with some good coffee on tap.