QnABot on AWS (an AWS Solution) now provides access to Amazon Bedrock foundational models (FMs) and Knowledge Bases for Amazon Bedrock, a fully managed end-to-end Retrieval Augmented Generation (RAG) workflow. You can now provide contextual information from your private data sources that can be used to create rich, contextual, conversational experiences.
The advent of generative artificial intelligence (AI) provides organizations unique opportunities to digitally transform customer experiences. Enterprises with contact center operations are looking to improve customer satisfaction by providing self-service, conversational, interactive chat bots that have natural language understanding (NLU). Enterprises want to automate frequently asked transactional questions, provide a friendly conversational interface, and improve operational efficiency. In turn, customers can ask a variety of questions and receive accurate answers powered by generative AI.
In this post, we discuss how to use QnABot on AWS to deploy a fully functional chatbot integrated with other AWS services, and delight your customers with human agent like conversational experiences.
Solution overview
QnABot on AWS is an AWS Solution that enterprises can use to enable a multi-channel, multi-language chatbot with NLU to improve end customer experiences. QnABot provides a flexible, tiered conversational interface empowering enterprises to meet customers where they are and provide accurate responses. Some responses need to be exact (for example, regulated industries like healthcare or capital markets), some responses need to be searched from large, indexed data sources and cited, and some answers need to be generated on the fly, conversationally, based on semantic context. With QnABot on AWS, you can achieve all of the above by deploying the solution using an AWS CloudFormation template, with no coding required. The solution is extensible, uses AWS AI and machine learning (ML) services, and integrates with multiple channels such as voice, web, and text (SMS).
QnABot on AWS provides access to multiple FMs through Amazon Bedrock, so you can create conversational interfaces based on your customers’ language needs (such as Spanish, English, or French), sophistication of questions, and accuracy of responses based on user intent. You now have the capability to access various large language models (LLMs) from leading AI enterprises (such as Amazon Titan, Anthropic Claude 3, Cohere Command, Meta Llama 3, Mistal AI Large Model, and others on Amazon Bedrock) to find a model best suited for your use case. Additionally, native integration with Knowledge Bases for Amazon Bedrock allows you to retrieve specific, relevant data from your data sources via pre-built data source connectors (Amazon Simple Storage Service – S3, Confluence, Microsoft SharePoint, Salesforce, or web crawlers), and automatically converted to text embeddings stored in a vector database of your choice. You can then retrieve your company-specific information with source attribution (such as citations) to improve transparency and minimize hallucinations. Lastly, if you don’t want to set up custom integrations with large data sources, you can simply upload your documents and support multi-turn conversations. With prompt engineering, managed RAG workflows, and access to multiple FMs, you can provide your customers rich, human agent-like experiences with precise answers.
Deploying the QnABot solution builds the following environment in the AWS Cloud.
Figure 1: QnABot Architecture Diagram
The high-level process flow for the solution components deployed with the CloudFormation template is as follows:
The admin deploys the solution into their AWS account, opens the Content Designer UI or Amazon Lex web client, and uses Amazon Cognito to authenticate.
After authentication, Amazon API Gateway and Amazon S3 deliver the contents of the Content Designer UI.
The admin configures questions and answers in the Content Designer and the UI sends requests to API Gateway to save the questions and answers.
The Content Designer AWS Lambda function saves the input in Amazon OpenSearch Service in a questions bank index. If using text embeddings, these requests first pass through a LLM model hosted on Amazon Bedrock or Amazon SageMaker to generate embeddings before being saved into the question bank on OpenSearch Service.
Users of the chatbot interact with Amazon Lex through the web client UI, Amazon Alexa, or Amazon Connect.
Amazon Lex forwards requests to the Bot Fulfillment Lambda function. Users can also send requests to this Lambda function through Amazon Alexa devices.
The user and chat information is stored in Amazon DynamoDB to disambiguate follow-up questions from previous question and answer context.
The Bot Fulfillment Lambda function takes the user’s input and uses Amazon Comprehend and Amazon Translate (if necessary) to translate non-native language requests to the native language selected by the user during the deployment, and then looks up the answer in OpenSearch Service. If using LLM features such as text generation and text embeddings, these requests first pass through various LLM models hosted on Amazon Bedrock or SageMaker to generate the search query and embeddings to compare with those saved in the question bank on OpenSearch Service.
If no match is returned from the OpenSearch Service question bank, then the Bot Fulfillment Lambda function forwards the request as follows:
If an Amazon Kendra index is configured for fallback, then the Bot Fulfillment Lambda function forwards the request to Amazon Kendra if no match is returned from the OpenSearch Service question bank. The text generation LLM can optionally be used to create the search query and synthesize a response from the returned document excerpts.
If a knowledge base ID is configured, the Bot Fulfillment Lambda function forwards the request to the knowledge base. The Bot Fulfillment Lambda function uses the RetrieveAndGenerate API to fetch the relevant results for a user query, augment the FM’s prompt, and return the response.
User interactions with the Bot Fulfillment function generate logs and metrics data, which is sent to Amazon Kinesis Data Firehose and then to Amazon S3 for later data analysis.
OpenSearch Dashboards can be used to view usage history, logged utterances, no hits utterances, positive user feedback, and negative user feedback, and also provides the ability to create custom reports.
Prerequisites
To get started, you need the following:
An AWS account
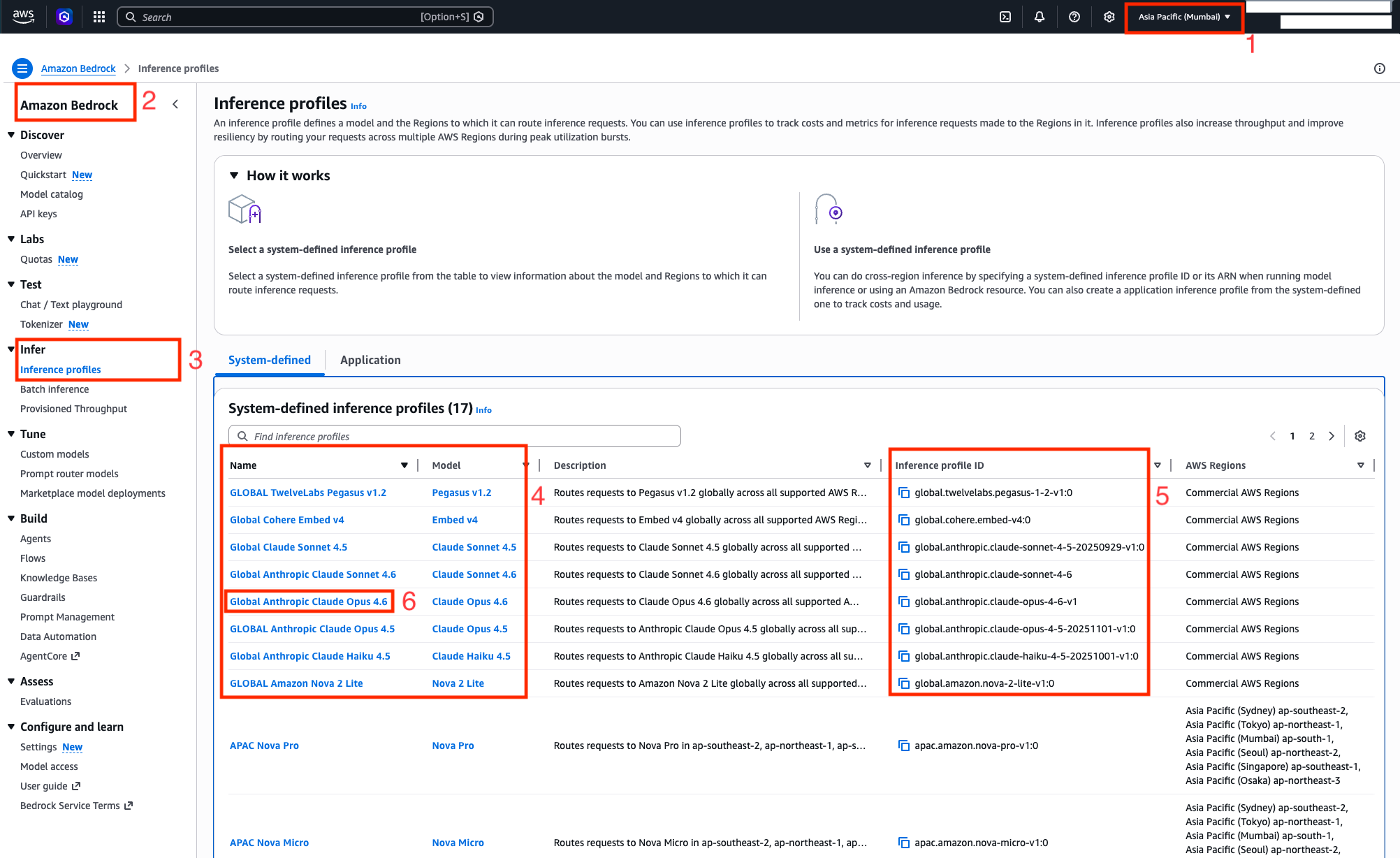
An active deployment of QnABot on AWS (version 6.0.0 or later)
Amazon Bedrock model access (required) for all embeddings and LLM models that will be used in QnABot
Figure 2: Request Access to Bedrock Foundational Models (FMs)
The Amazon Bedrock knowledge base ID (create a knowledge base in Amazon Bedrock if you want to chat with your documents)
In the following sections, we explore some of QnABot’s generative AI features.
Semantic question matching using an embeddings LLM
QnABot on AWS can use text embeddings to provide semantic search capabilities by using LLMs. The goal of this feature is to improve question matching accuracy while reducing the amount of tuning required when compared to the default OpenSearch Service keyword-based matching.
Some of the benefits include:
Improved FAQ accuracy from semantic matching vs. keyword matching (comparing the meaning vs. comparing individual words)
Fewer training utterances required to match a diverse set of queries
Better multi-language support, because translated utterances only need to match the meaning of the stored text, not the wording
Configure Amazon Bedrock to enable semantic question matching
To enable these expanded semantic search capabilities, QnABot uses an Amazon Bedrock FM to generate text embeddings provided using the EmbeddingsBedrockModelId CloudFormation stack parameter. These models provide the best performance and operate on a pay-per-request model. At the time of writing, the following embeddings models are supported by QnABot on AWS:
Amazon Titan Embeddings G1
Cohere English
Cohere Multilingual
For the CloudFormation stack, set the following parameters:
Set EmbeddingsAPI to BEDROCK
Set EmbeddingsBedrockModelId to one of the available options
For example, with semantic matching enabled, the question “What’s the address of the White House?” matches to “Where does the President live?” This example doesn’t match using keywords because they don’t share any of the same words.
Figure 3: Semantic matching in QnABot
In the UI designer, you can set ENABLE_DEBUG_RESPONSE to true to see the user input, source, or any errors of the answer, as illustrated in the preceding screenshot.
You can also evaluate the matching score on the TEST tab in the content designer UI. In this example, we add a match on “qna item question” with the question “Where does the President live?”
Figure 4: Test and evaluate answers in QnABot
Similarly, you can try a match on “item text passage” with the question “Where did Humpty Dumpty sit?”
Figure 5: Match items or text passages in QnABot
Recommendations for tuning with an embeddings LLM
When using embeddings in QnABot, we recommend generalizing questions because more user utterances will match a general statement. For example, the embeddings LLM model will cluster “checking” and “savings” with “account,” so if you want to match both account types, use “account” in your questions.
Similarly, for the question and utterance of “transfer to an agent,” consider using “transfer to someone” because it will better match with “agent,” “representative,” “human,” “person,” and so on.
In addition, we recommend tuning EMBEDDINGS_SCORE_THRESHOLD, EMBEDDINGS_SCORE_ANSWER_THRESHOLD, and EMBEDDINGS_TEXT_PASSAGE_SCORE_THRESHOLD based on the scores. The default values are generalized to all multiple models, but you might need to modify this based on embeddings model and your experiments.
Text generation and query disambiguation using a text LLM
QnABot on AWS can use LLMs to provide a richer, more conversational chat experience. The goal of these features is to minimize the amount of individually curated answers administrators are required to maintain, improve question matching accuracy by providing query disambiguation, and enable the solution to provide more concise answers to users, especially when using a knowledge base in Amazon Bedrock or the Amazon Kendra fallback feature.
Configure an Amazon Bedrock FM with AWS CloudFormation
To enable these capabilities, QnABot uses one of the Amazon Bedrock FMs to generate text embeddings provided using the LLMBedrockModelId CloudFormation stack parameter. These models provide the best performance and operate on a pay-per-request model.
For the CloudFormation stack, set the following parameters:
Set LLMApi to BEDROCK
Set LLMBedrockModelId to one of the available LLM options
Figure 6: Setup QnABot to use Bedrock FMs
Query disambiguation (LLM-generated query)
By using an LLM, QnABot can take the user’s chat history and generate a standalone question for the current utterance. This enables users to ask follow-up questions that on their own may not be answerable without context of the conversation. The new disambiguated, or standalone, question can then be used as search queries to retrieve the best FAQ, passage, or Amazon Kendra match.
In QnABot’s Content Designer, you can further customize the prompt and model listed in the Query Matching section:
LLM_GENERATE_QUERY_PROMPT_TEMPLATE – The prompt template used to construct a prompt for the LLM to disambiguate a follow-up question. The template may use the following placeholders:
history – A placeholder for the last LLM_CHAT_HISTORY_MAX_MESSAGES messages in the conversational history, to provide conversational context.
input – A placeholder for the current user utterance or question.
LLM_GENERATE_QUERY_MODEL_PARAMS – The parameters sent to the LLM model when disambiguating follow-up questions. Refer to the relevant model documentation for additional values that the model provider accepts.
The following screenshot shows an example with the new LLM disambiguation feature enabled, given the chat history context after answering “Who was Little Bo Peep” and the follow-up question “Did she find them again?”
Figure 7: LLM query disambiguation feature enabled
QnABot rewrites that question to provide all the context required to search for the relevant FAQ or passage: “Did Little Bo Peep find her lost sheep again?”
Figure 8: With query disambiguation with LLMs, context is maintained
Answer text generation using QnABot
You can now generate answers to questions from context provided by knowledge base search results, or from text passages created or imported directly into QnABot. This allows you to generate answers that reduce the number of FAQs you have to maintain, because you can now synthesize concise answers from your existing documents in a knowledge base, Amazon Kendra index, or document passages stored in QnABot as text items. Additionally, your generated answers can be concise and therefore suitable for voice or contact center chatbots, website bots, and SMS bots. Lastly, these generated answers are compatible with the solution’s multi-language support—customers can interact in their chosen languages and receive generated answers in the same language.
With QnABot, you can use two different data sources to generate responses: text passages or a knowledge base in Amazon Bedrock.
Generate answers to questions from text passages
In the content designer web interface, administrators can store full text passages for QnABot on AWS to use. When a question gets asked that matches against this passage, the solution can use LLMs to answer the user’s question based on information found within the passage. We highly recommend you use this option with semantic question matching using Amazon Bedrock text embedding. In QnABot content designer, you can further customize the prompt and model listed under Text Generation using the General Settings section.
Let’s look at a text passage example:
In the Content Designer, choose Add.
Select the text, enter an item ID and a passage, and choose Create.
You can also import your passages from a JSON file using the Content Designer Import feature. On the tools menu, choose Import, open Examples/Extensions, and choose LOAD next to TextPassage-NurseryRhymeExamples to import two nursery rhyme text items.
The following example shows QnABot generating an answer using a text passage item that contains the nursery rhyme, in response to the question “Where did Humpty Dumpty sit?”
Figure 9: Generate answers from text passages
You can also use query disambiguation and text generation together, by asking “Who tried to fix Humpty Dumpty?” and the follow-up question “Did they succeed?”
Figure 10: Text generation with query disambiguation to maintain context
You can also modify LLM_QA_PROMPT_TEMPLATE in the Content Designer to answer in different languages. In the prompt, you can specify the prompt and answers in different languages (e.g. prompts in French, Spanish).
Figure 11: Answer in different languages
You can also specify answers in two languages with bulleted points.
Figure 12: Answer in multiple languages
RAG using an Amazon Bedrock knowledge base
By integrating with a knowledge base, QnABot on AWS can generate concise answers to users’ questions from configured data sources. This prevents the need for users to sift through larger text passages to find the answer. You can also create your own knowledge base from files stored in an S3 bucket. Amazon Bedrock knowledge bases with QnABot don’t require EmbeddingsApi and LLMApi because the embeddings and generative response are already provided by the knowledge base. To enable this option, create an Amazon Bedrock knowledge base and use your knowledge base ID for the CloudFormation stack parameter BedrockKnowledgeBaseId.
To configure QnABot to use the knowledge base, refer to Create a knowledge base. The following is a quick setup guide to get started:
Provide your knowledge base details.
Figure 13: Setup Amazon Bedrock Knowledge Base for RAG use cases
Configure your data source based on the available options. For this example, we use Amazon S3 as the data source and note that the bucket has to be prepended with qna or QNA.
Figure 14: Setup your RAG data sources for Amazon Knowledge Base
Upload your documents to Amazon S3. For this example, we uploaded the aws-overview.pdf whitepaper to test integration.
Create or choose your vector database store to allow Bedrock to store, update and manage embeddings.
Sync the data source and use your knowledge base ID for the CloudFormation stack parameter BedrockKnowledgeBaseId.
Figure 15: Complete setting up Amazon Bedrock Knowledge Base for your RAG use cases
In QnABot Content Designer, you can customize additional settings list under Text Generation using RAG with the Amazon Bedrock knowledge base.
QnABot on AWS can now answer questions from the AWS whitepapers, such as “What services are available in AWS for container orchestration?” and “Are there any upfront fees with ECS?”
Figure 16: Generate answers from your Amazon Bedrock Knowledge Base (RAG)
Conclusion
Customers expect quick and efficient service from enterprises in today’s fast-paced world. But providing excellent customer experience can be significantly challenging when the volume of inquiries outpaces the human resources employed to address them. Companies of all sizes can use QnABot on AWS with built-in Amazon Bedrock integrations to provide access to many market leading FMs, provide specialized lookup needs using RAG to reduce hallucinations, and provide a friendly AI conversational experience. With QnABot on AWS, you can provide high-quality natural text conversations, content management, and multi-turn dialogues. The solution comes with one-click deployment for custom implementation, a content designer for Q&A management, and rich reporting. You can also integrate with contact center systems like Amazon Connect and Genesys Cloud CX. Get started with QnABot on AWS.
About the Author
Ajay Swamy is the Product Leader for Data, ML and Generative AI AWS Solutions. He specializes in building AWS Solutions (production-ready software packages) that deliver compelling value to customers by solving for their unique business needs. Other than QnABot on AWS, he manages Generative AI Application Builder, Enhanced Document Understanding, Discovering Hot Topics using Machine Learning and other AWS Solutions. He lives with his wife and dog (Figaro), in New York, NY.
Abhishek Patil is a Software Development Engineer at Amazon Web Services (AWS) based in Atlanta, GA, USA. With over 7 years of experience in the tech industry, he specializes in building distributed software systems, with a primary focus on Generative AI and Machine Learning. Abhishek is a primary builder on AI solution QnABot on AWS and has contributed to other AWS Solutions including Discovering Hot Topics using Machine Learning and OSDU® Data Platform. Outside of work, Abhishek enjoys spending time outdoors, reading, resistance training, and practicing yoga.