Amazon Bedrock has enabled customers to build new delightful experiences for their customers using generative artificial intelligence (AI). Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities that you need to build generative AI applications with security, privacy, and responsible AI. With some of the best FMs available at their fingertips within Amazon Bedrock, customers are experimenting and innovating faster than ever before. As customers look to operationalize these new generative AI applications, they also need prescriptive, out-of-the-box ways to monitor the health and performance of these applications.
In this blog post, we will share some of capabilities to help you get quick and easy visibility into Amazon Bedrock workloads in context of your broader application. We will use the contextual conversational assistant example in the Amazon Bedrock GitHub repository to provide examples of how you can customize these views to further enhance visibility, tailored to your use case. Specifically, we will describe how you can use the new automatic dashboard in Amazon CloudWatch to get a single pane of glass visibility into the usage and performance of Amazon Bedrock models and gain end-to-end visibility by customizing dashboards with widgets that provide visibility and insights into components and operations such as Retrieval Augmented Generation in your application.
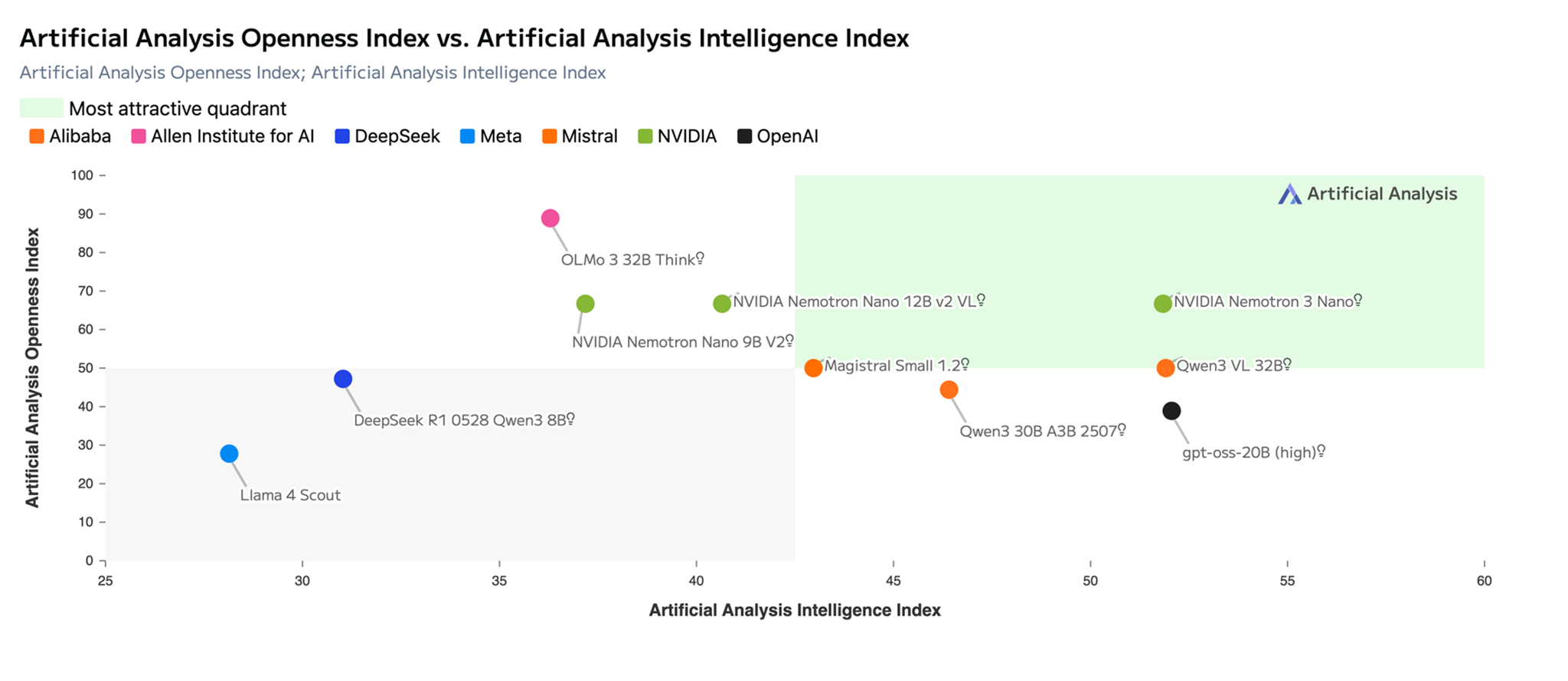
Announcing Amazon Bedrock automatic dashboard in CloudWatch
CloudWatch has automatic dashboards for customers to quickly gain insights into the health and performance of their AWS services. A new automatic dashboard for Amazon Bedrock was added to provide insights into key metrics for Amazon Bedrock models.
To access the new automatic dashboard from the AWS Management Console:
Select Dashboards from the CloudWatch console, and select the Automatic Dashboards tab. You’ll see an option for an Amazon Bedrock dashboard in the list of available dashboards.
Figure 1: From Dashboards in the CloudWatch console, you can find Automatic Dashboards for Amazon Bedrock workloads
Select Bedrock from the list of automatic dashboards to instantiate the dashboard. From here you can gain centralized visibility and insights to key metrics such as latency and invocation metrics. A better understanding of latency performance is critical for customer facing applications of Amazon Bedrock such as conversational assistants. It’s very important to know if your models are providing outputs in a consistent, timely manner to ensure an adequate experience for your customers.
Figure 2: Automatic dashboard with insights into Amazon Bedrock invocation performance and token usage.
The automatic dashboard automatically collects key metrics across foundation models provided through Amazon Bedrock. Optionally, you can select a specific model to isolate the metrics to one model. Monitor Amazon Bedrock with Amazon CloudWatch provides a detailed list of Amazon Bedrock metrics (such as invocation performance and token usage) available in CloudWatch.
Figure 3: Automatic dashboard has a widget to review invocation latency isolated to one model
With the new automatic dashboard, you have a single pane of glass view on key metrics that you can use to troubleshoot common challenges such as invocation latency, track token usage, and detect invocation errors.
Building custom dashboards
In addition to the automatic dashboard, you can use CloudWatch to build customized dashboards that combine metrics from multiple AWS services to create application-level dashboards. This is important not only for monitoring performance but also for debugging and for implementing custom logic to react to potential issues. Additionally, you can use the custom dashboard to analyze invocation logs generated from your prompts. This is helpful in gathering information that’s unavailable in metrics such as identity attribution. With the machine learning capabilities provided by AWS, you can detect and protect sensitive data in your logs as well.
A popular choice for customizing models for a specific use case is to implement Retrieval Augmented Generation (RAG), allowing you to augment the model with domain specific data. With RAG-based architectures, you’re combining multiple components including external knowledge sources, models, and compute required to perform the orchestration and implementation of a RAG based workflow. This requires several components, all of which need to be monitored as part of your overall monitoring strategy. In this section, you’ll learn how to create a custom dashboard using an example RAG based architecture that utilizes Amazon Bedrock.
This blog post builds on the contextual conversational assistant example to create a custom dashboard that provides visibility and insights into the core components of a sample RAG based solution. To replicate the dashboard in your AWS account, follow the contextual conversational assistant instructions to set up the prerequisite example prior to creating the dashboard using the steps below.
After you have set up the contextual conversational assistant example, generate some traffic by experimenting with the sample applications and trying different prompts.
To create and view the custom CloudWatch dashboard for the contextual conversational assistant app:
Modify and run this example of creating a custom CloudWatch dashboard for the contextual conversational assistant example.
Go to Amazon CloudWatch from within the console and select Dashboards from the left menu.
Figure: 4 In the CloudWatch console you have the option to create custom dashboards
Under Custom Dashboards, you should see a dashboard called Contextual-Chatbot-Dashboard. This dashboard provides a holistic view of metrics pertaining to:
The number of invocations and token usage that the Amazon Bedrock embedding model used to create your knowledge base and embed user queries as well as the Amazon Bedrock model used to respond to user queries given the context provided by the knowledge base. These metrics help you track anomalies in the usage of the application as well as cost.
The context retrieval latency for search requests and ingestion requests. This helps you to gauge the health of the RAG retrieval process.
The number of the indexing and search operations on the OpenSearch Serverless collection that was created when you created your knowledge base. This helps you to monitor the status of the OpenSearch collection being used in the application and could quickly isolate the scope of RAG issues, such as errors in retrieval.
Determine invocation usage attribution to specific users. For example, you can find out exactly who is using how many tokens or invocations. (Details are in the Usage Attribution section that follows).
Keep track of the number of throttles of the Lambda function that ties the application together. This gives you key health metrics of the Lambda functions that are orchestrating the application.
Figure 5: The Contextual-assistant-Dashboard is a custom CloudWatch dashboard provides a holistic view with visibility into you lambda functions, context retrieval latency, and OpenSearch Serverless collection.
Usage attribution
When you want to monitor the invocation usage from multiple different applications or users, you can use Amazon Bedrock invocation logs for better visibility of the origin and token consumption for each invocation. The following is an example invocation log from Amazon Bedrock, which, along with other vital information about a given invocation, includes the identity.arn of the user who made that invocation.
Figure 6: CloudWatch Logs provides real time, detailed visibility into your invocation logs
You can use CloudWatch Logs Insights to get a breakdown of usage by identity across your Amazon Bedrock invocations. For example, you can write a Logs Insights query to calculate the token usage of the various applications and users calling the large language model (LLM). In Logs Insights, first choose the Amazon Bedrock invocation log group, and then you can write a query to filter on the identity.arn and input and output token counts, and then aggregate on the stats to give you a sum of the token usage by ARN.
fields @timestamp, identity.arn, input.inputTokenCount, output.outputTokenCount
| stats sum(input.inputTokenCount) as totalInputTokens,
sum(output.outputTokenCount) as totalOutputTokens,
count(*) as invocationCount by identity.arn
You can also add this query to the dashboard for continuous monitoring by choosing Add to dashboard.
Figure 7: CloudWatch Log Insights can help you understand the drivers of your invocation logs by applications
In the Add to dashboard menu, you can add the results to an existing dashboard or add a new dashboard.
Figure 8: You can add widgets to your CloudWatch dashboards.
With the information from logs included in your custom dashboard, you now have a single pane of glass visibility into the health, performance, and usage of your conversational assistant application.
Figure 9: You can use existing CloudWatch existing templates for Amazon Bedrock as a starting point to create a single pane of glass dashboard tailored to your specific needs
To help you get started, you can access the template of the custom dashboard code on Github to create your own custom dashboard in your CloudWatch console.
Conclusion
In this blog post, we highlighted three common challenges customers face while operationalizing generative AI applications:
Having single pane of glass visibility into performance of Amazon Bedrock models.
Keeping Amazon Bedrock monitoring alongside other components that make up the overall application.
Attributing LLM usage to specific users or applications.
In CloudWatch, you can use automatic dashboards to monitor Amazon Bedrock metrics and create your own customized dashboards to monitor additional metrics specific to your application such as the health of RAG retrievals. We also showed you how you can use CloudWatch Logs Insights query to extract usage attribution by application/user and add it as a logs widget in your customized dashboard for continuous monitoring. You can get started with Amazon Bedrock monitoring with the example of contextual conversational assistant example provided in Amazon Bedrock GitHub repository and a template of the custom dashboard in this GitHub repository.
About the authors
Peter Geng is a Senior Product Manager with Amazon CloudWatch. He focuses on monitoring and operationalizing cloud and LLM workloads in CloudWatch for AWS customers. Peter has experience across cloud observability, LLMOps, and AIOps. He holds an MBA and Masters of Science from University of California, Berkeley.
Nikhil Kapoor is a Principal Product Manager with Amazon CloudWatch. He leads logs ingestion and structured logging capabilities within CloudWatch with the goal of making log analysis simpler and more powerful for our customers. Nikhil has 15+ years of industry experience, specializing in observability and AIOps.
Shelbee Eigenbrode is a Principal AI and Machine Learning Specialist Solutions Architect at Amazon Web Services (AWS). She has been in technology for 24 years spanning multiple industries, technologies, and roles. She is currently focusing on combining her DevOps and ML background into the domain of MLOps to help customers deliver and manage ML workloads at scale. With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes. Shelbee is a co-creator and instructor of the Practical Data Science specialization on Coursera. She is also the Co-Director of Women In Big Data (WiBD), Denver chapter. In her spare time, she likes to spend time with her family, friends, and overactive dogs.
Michael Wishart is the NAMER Lead for Cloud Operations at AWS. He is responsible for helping customers solve their observability and governance challenges with AWS native services. Prior to AWS, Michael led business development activities for B2B technology companies across semiconductors, SaaS, and autonomous trucking industries.
Bobby Lindsey is a Machine Learning Specialist at Amazon Web Services. He’s been in technology for over a decade, spanning various technologies and multiple roles. He is currently focused on combining his background in software engineering, DevOps, and machine learning to help customers deliver machine learning workflows at scale. In his spare time, he enjoys reading, research, hiking, biking, and trail running.