Recent advances in artificial intelligence have led to the emergence of generative AI that can produce human-like novel content such as images, text, and audio. These models are pre-trained on massive datasets and, to sometimes fine-tuned with smaller sets of more task specific data. An important aspect of developing effective generative AI application is Reinforcement Learning from Human Feedback (RLHF). RLHF is a technique that combines rewards and comparisons, with human feedback to pre-train or fine-tune a machine learning (ML) model. Using evaluations and critiques of its outputs, a generative model can continue to refine and improve its performance. The interplay between Generative AI and human input paves the way for more accurate and responsible applications. You can learn how to improve your LLMs with RLHF on Amazon SageMaker, see Improving your LLMs with RLHF on Amazon SageMaker.
Athough RLHF is the predominant technique for incorporating human involvement, it is not the only available human in the loop technique. RLHF is an offline, asynchronous technique, where humans provide feedback on the generated outputs, based on input prompts. Humans can also add value by intervening into an existing communication happening between generative AI and users. For instance, as decided by AI or desired by the user, a human can be called into an existing conversation and take over the discussion.
In this post, we introduce a solution for integrating a “near-real-time human workflow” where humans are prompted by the generative AI system to take action when a situation or issue arises. This can also be a ruled-based method that can determine where, when and how your expert teams can be part of generative AI – user conversations. The entire conversation in this use case, starting with generative AI and then bringing in human agents who take over, is logged so that the interaction can be used as part of the knowledge base. Together with RLHF, near-real-time human-in-the-loop methods enable the development of responsible and effective generative AI applications.
This blog post uses RLHF as an offline human-in-the-loop approach and the near-real-time human intervention as an online approach. We present the solution and provide an example by simulating a case where the tier one AWS experts are notified to help customers using a chat-bot. We use an Amazon Titan model on Amazon Bedrock to find the sentiment of the customer using a Q&A bot and then notifying about negative sentiment to a human to take the appropriate actions. We also have another expert group providing feedback using Amazon SageMaker GroundTruth on completion quality for the RLHF based training. We used this feedback to finetune the model deployed on Amazon Bedrock to power the chat-bot. We provide LangChain and AWS SDK code-snippets, architecture and discussions to guide you on this important topic.
SageMaker GroudTruth
SageMaker Ground Truth offers the most comprehensive set of human-in-the-loop capabilities, allowing you to harness the power of human feedback across the ML lifecycle to improve the accuracy and relevancy of models. You can complete a variety of human-in-the-loop tasks with SageMaker Ground Truth, from data generation and annotation to model review, customization, and evaluation, through either a self-service or an AWS-managed offering.
Amazon Bedrock
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon with a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI. With Amazon Bedrock, you can easily experiment with and evaluate top FMs for your use case, privately customize them with your data using techniques such as fine-tuning and Retrieval Augmented Generation (RAG), and build agents that run tasks using your enterprise systems and data sources. Because Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with.
Example use-case
In this use case, we work with a generative AI powered Q&A bot, which answers questions about SageMaker. We built the RAG solution as detailed in the following GitHub repo and used SageMaker documentation as the knowledge base. You can build such chatbots following the same process. The interface of the Q&A looks like the following screenshot. Amazon SageMaker Sample and used Amazon SageMaker documentation as the knowledge base. You can easily build such chatbots following the same process. Eventually, the interface of the Q&A looks like in Figure 1.
Figure 1. UI and the Chatbot example application to test human-workflow scenario.
In this scenario, we incorporate two human workflows to increase customer satisfaction. The first is to send the interactions to human experts to assess and provide scores. This is an offline process that is part of the RLHF. A second real-time human workflow is initiated as decided by the LLM. We use a simple notification workflow in this post, but you can use any real-time human workflow to take over the AI-human conversation.
Solution overview
The solution consists of three main modules:
Near real-time human engagement workflow
Offline human feedback workflow for RLHF
Fine-tuning and deployment for RLHF
The RLHF and real-time human engagement workflows are independent. Therefore, you can use either or both based on your needs. In both scenarios, fine-tuning is a common final step to incorporate these learnings into LLMs. In the following sections, we provide the details about incorporating these steps one by one and divide the solution into related sections for you to choose and deploy.
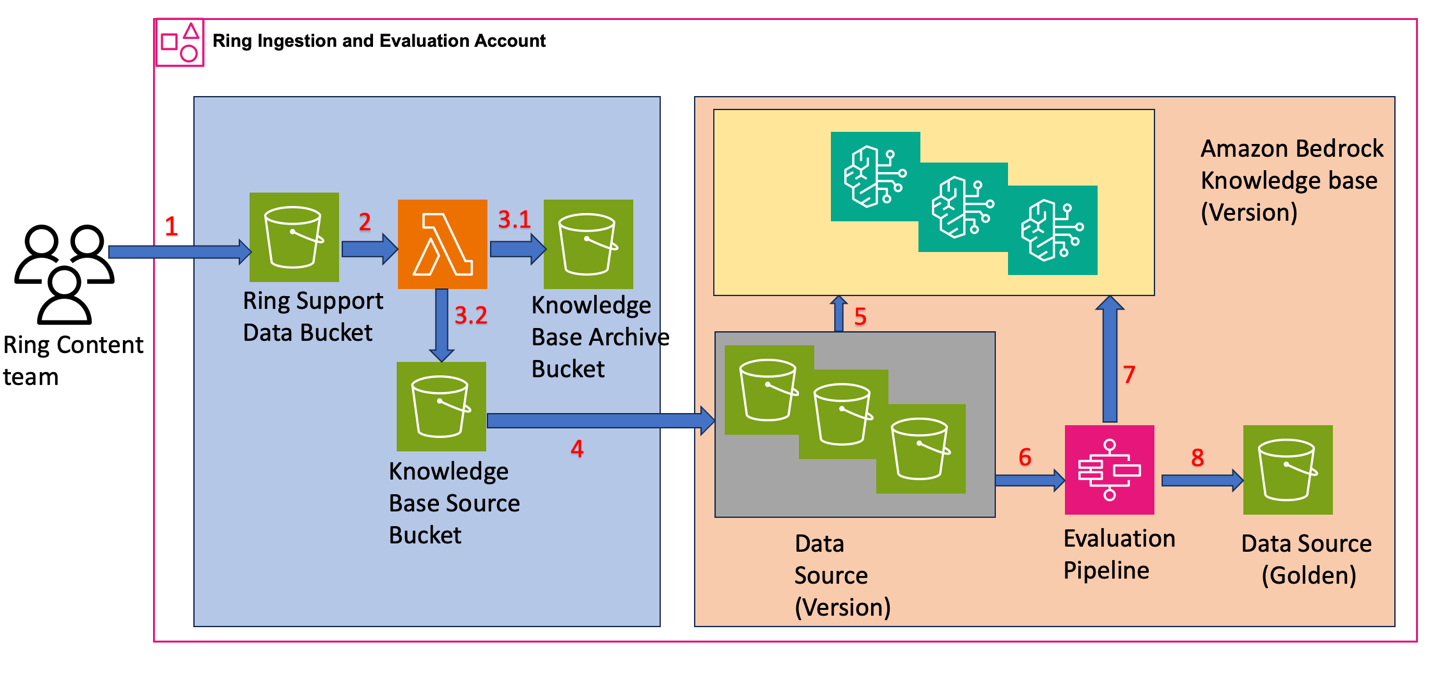
The following diagram illustrates the solution architecture and workflow.
Figure 2. Solutions architecture for human-machine workflow modules
Implementation
Prerequisites
Our solution is an add-on to an existing Generative AI application. In our example, we used a Q&A chatbot for SageMaker as explained in the previous section. However, you can also bring your own application. The blog post assumes that you have expert teams or workforce who performs reviews or join workflows.
Build a near real-time human engagement workflow workflow
This section presents how an LLM can invoke a human workflow to perform a predefined activity. We use AWS Step Functions which is a serverless workflow orchestration service that you can use for human-machine workflows. In our case, we call the human experts into action, in real time, but you can build any workflow following the tutorial Deploying an Example Human Approval Project.
Decision workflow to trigger real time human engagement
In this scenario, the customer interacts with the Q&A bot (Step-1 in the previous architecture diagram), and if the interaction shows strong negative sentiment, it will invoke a pre-existing human workflow (Step-2 in Figure 2). In our case, it is a simple email notification (Step-3 in Figure 2) but you can extend this interaction such as including the experts into the chat-zone to take over the conversation and more (Step-4 in Figure 2).
Before we dive deep into the solution, it is important to discuss the workflow logic. The following figure shows the details of the decision workflow. The interaction starts with a customer communication. Here, before the LLM provides an answer to the customer request, the prompt-chain starts with an internal prompt asking the LLM to go over the customer response and look for clear negative sentiment. This prompt and internal sentiment analysis are not visible to customer. This is an internal chain before proceeding with the next steps of which responses may be reflected to the customer based on your preference. If the sentiment is negative, the next step is to trigger a pre-built engagement human-workflow while the chatbot informs the customer about the extra support coming to help. Otherwise, if the sentiment is neutral or positive, the normal response to the customer request will be provided.
This workflow is a demonstrative example and you can add to or modify it as you prefer. For example, you can make any other decision check, not limited to sentiment. You can also prepare your own response to the customer with the right prompting the chain so that you can implement your designed customer experience. Here, our simple example demonstrates how you can easily build such prompt in chains and engage external existing workflows, in our case, it is a human-workflow using Amazon Bedrock. We also use the same LLM to respond to this internal sentiment prompt check for simplicity. However, you can include different LLMs, which might have been fine-tuned for specific tasks, such as sentiment analysis, so that you rely on a different LLM for the Q&A chatbot experience. Adding more serial steps into chains increases the latency because now the customer query or request is being processed more than once.
Figure 3. Real-time (online) human workflow triggered by LLM.
Implementing the decision workflow with Amazon Bedrock
To implement the decision workflow, we used Amazon Bedrock and its LangChain integrations. The prompt chain is run through SequentialChain from LangChain. Because our human workflow is orchestrated with Step Functions, we also use LangChain’s StepFunction library.
First, define the LLM and prompt template:
Then you feed the response from the first LLM to the next LLM through an LLM chain, where the second instruct is to find the sentiment of the response. We also instruct the LLM to provide 0 as positive and 1 as negative response.
Run a sequential chain to find the sentiment:
If the sentiment is negative, the model doesn’t provide the response back to customer, instead it invokes a workflow that will notify a human in loop:
If you choose to have your human experts join a chat with the users, you can add these interactions of your expert teams to your knowledge base. This way, when the same or similar issue is raised, the chatbot can use these in their answers. In this post, we did not show this method, but you can create a knowledge base in Amazon Bedrock to use these human-to-human interactions for future conversations in your chatbot.
Build an offline human feedback workflow
In this scenario, we assume that the chat transcripts are stored in an Amazon Simple Storage Service (Amazon S3) bucket in JSON format, a typical chat transcript format, for the human experts to provide annotations and labels on each LLM response. The transcripts are sent for a labeling task performed by a labeling workforce using Amazon SageMaker Ground Truth. However, in some cases, it’s impossible to label all the transcripts due to resource limitations. In these cases, you may want to randomly sample the transcripts or use a pattern that can be sent to the labeling workforce based on your business case.
Pre-annotation Lambda function
The process starts with an AWS Lambda function. The pre-annotation Lambda function is invoked based on chron job or based on an event or on-demand. Here, we use the on-demand option. SageMaker Ground Truth sends the Lambda function a JSON-formatted request to provide details about the labeling job and the data object. More information can be found here. Following is the code snippet for the pre-processing Lambda function:
Custom workflow for SageMaker Ground Truth
The remaining part of sending the examples, UI, and storing the results of the feedback are performed by SageMaker Ground Truth and invoked by the pre-annotation Lambda function. We use the labeling job with the custom template option in SageMaker Ground Truth. The workflow allows labelers to rate the relevance of an answer to a question from 1–5, with 5 being the most relevant. Here, we assumed a conventional RLHF workflow where the labeling workforce provides the score based on their expectation from the LLM in this situation. The following code shows an example:
In our scenario, we used the following UI for our labeling workers to score the complete response given for the prompt. This provides feedback on the answer to a question given by the chatbot, marking it as 1–5, with 5 being most the relevant answer to the question.
Figure 4. Two examples from RLHF feedback UI.
Post annotation Lambda function
When all workers complete the labeling task, SageMaker Ground Truth invokes the post-annotation Lambda function with a pointer to the dataset object and the workers’ annotations. This post-processing Lambda function is generally used for annotation consolidation, which has SageMaker Ground Truth create a manifest file and uploads it to an S3 bucket for persistently storing consolidated annotations. The following code shows the postprocessing Lambda function:
You can use the output manifest file to further fine-tune your LLM model, as detailed in the next section. The following code is a snippet of the created manifest file:
Fine-tune the LLM using RLHF
To demonstrate RLHF in both near real-time and offline workflows, we collected 50 human-annotated samples using SageMaker Ground Truth. The data is used for RLHF training on a Flan-T5 XL model by PEFT/LoRA with 8-bit quantization:
The training uses the learning rate 1e-5 for 10 epochs, and the batch size = 1 to use one sample at a time.
Because there are only 50 human-annotated samples collected from SageMaker Ground Truth, it is not sufficient to train a reward model for reinforcement learning. Therefore, we decided to take the annotated evaluation score for each sample and use them as the reward value in the reinforcement learning process. This should be close enough to the reward value generated from a reward model. Our experiment showed that this method is effective for a small training set. You can see the curve of the training process in the following chart.
Figure 5. Reward/mean chart
After the training, we replaced the Flan-T5 foundation model in the AWS support chatbot with the RLHF trained model. In the following examples, you can observe that the response quality after RLHF is improved and the answers are more comprehensive and contain more useful information:
Question: How does SageMaker protect my data?
Response before RLHF: SageMaker stores code in ML storage volumes
Response after RLHF: SageMaker stores code in ML storage volumes, secured by security groups and optionally encrypted at rest.
Question: What is Amazon SageMaker?
Response before RLHF: AWS SageMaker is a machine learning service that allows you to train and deploy machine learning models in the cloud.
Response after RLHF: A fully managed service to prepare data and build, train, and deploy machine learning (ML) models for any use case with fully managed infrastructure, tools, and workflows.
Clean up
To clean up your resources, first start by stopping and deactivating any active human workflow or fine-tuning jobs. Removing the prompt chaining is a good start for de-coupling the workflows from your existing application. Then, continue by deleting the resources for the real-time human workflow manually. Finally, delete the RLHF resources. If you created a new Q&A chatbot application, then first stop and then delete the resources used for the Q&A chatbot part of the blogpost.
Conclusion
This post presented solutions for incorporating both offline and online human workflows into generative AI applications on AWS. The offline human feedback workflow uses SageMaker Ground Truth to collect human evaluations on chatbot responses. These evaluations are used to provide reward signals for fine-tuning the chatbot’s underlying language model with RLHF. The online human workflow uses LangChain and Step Functions to invoke real-time human intervention based on sentiment analysis of the chatbot responses. This allows human experts to seamlessly take over or step into conversations when the AI reaches its limits. This capability is important for implementations that require using your existing expert teams in critical, sensitive, or determined topics and themes. Together, these human-in-the-loop techniques, offline RLHF workflows, and online real-time workflows enable you to develop responsible and robust generative AI applications.
The provided solutions integrate multiple AWS services, like Amazon Bedrock, SageMaker, SageMaker Ground Truth, Lambda, Amazon S3, and Step Functions. By following the architectures, code snippets, and examples discussed in this post, you can start incorporating human oversight into your own generative AI applications on AWS. This paves the way towards higher-quality completions and building trustworthy AI solutions that complement and collaborate with human intelligence.
Building generative AI applications is effortless with Amazon Bedrock. We recommend starting your experiments following this Quick Start with Bedrock.
About the Authors
Tulip Gupta is a Senior Solutions Architect at Amazon Web Services. She works with Amazon media and entertainment (M&E) customers to design, build, and deploy technology solutions on AWS, and has a particular interest in Gen AI and machine learning focussed on M&E. She assists customers in adopting best practices while deploying solutions in AWS. Linkedin
Burak Gozluku is a Principal AI/ML Specialist Solutions Architect located in Boston, MA. He helps strategic customers adopt AWS technologies and specifically Generative AI solutions to achieve their business objectives. Burak has a PhD in Aerospace Engineering from METU, an MS in Systems Engineering, and a post-doc in system dynamics from MIT in Cambridge, MA. Burak is still a research affiliate in MIT. Burak is passionate about yoga and meditation.
Yunfei bai is a Senior Solutions Architect at AWS. With a background in AI/ML, data science, and analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and data analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei has a PhD in Electronic and Electrical Engineering. Outside of work, Yunfei enjoys reading and music.
Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in future and bring economical and social prosperity. In her spare time, Rachna likes spending time with her family, hiking and listening to music.