In the world of software development, code review and approval are important processes for ensuring the quality, security, and functionality of the software being developed. However, managers tasked with overseeing these critical processes often face numerous challenges, such as the following:
Lack of technical expertise – Managers may not have an in-depth technical understanding of the programming language used or may not have been involved in software engineering for an extended period. This results in a knowledge gap that can make it difficult for them to accurately assess the impact and soundness of the proposed code changes.
Time constraints – Code review and approval can be a time-consuming process, especially in larger or more complex projects. Managers need to balance between the thoroughness of review vs. the pressure to meet project timelines.
Volume of change requests – Dealing with a high volume of change requests is a common challenge for managers, especially if they’re overseeing multiple teams and projects. Similar to the challenge of time constraint, managers need to be able to handle those requests efficiently so as to not hold back project progress.
Manual effort – Code review requires manual effort by the managers, and the lack of automation can make it difficult to scale the process.
Documentation – Proper documentation of the code review and approval process is important for transparency and accountability.
With the rise of generative artificial intelligence (AI), managers can now harness this transformative technology and integrate it with the AWS suite of deployment tools and services to streamline the review and approval process in a manner not previously possible. In this post, we explore a solution that offers an integrated end-to-end deployment workflow that incorporates automated change analysis and summarization together with approval workflow functionality. We use Amazon Bedrock, a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon available via an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using AWS tools without having to manage any infrastructure.
Solution overview
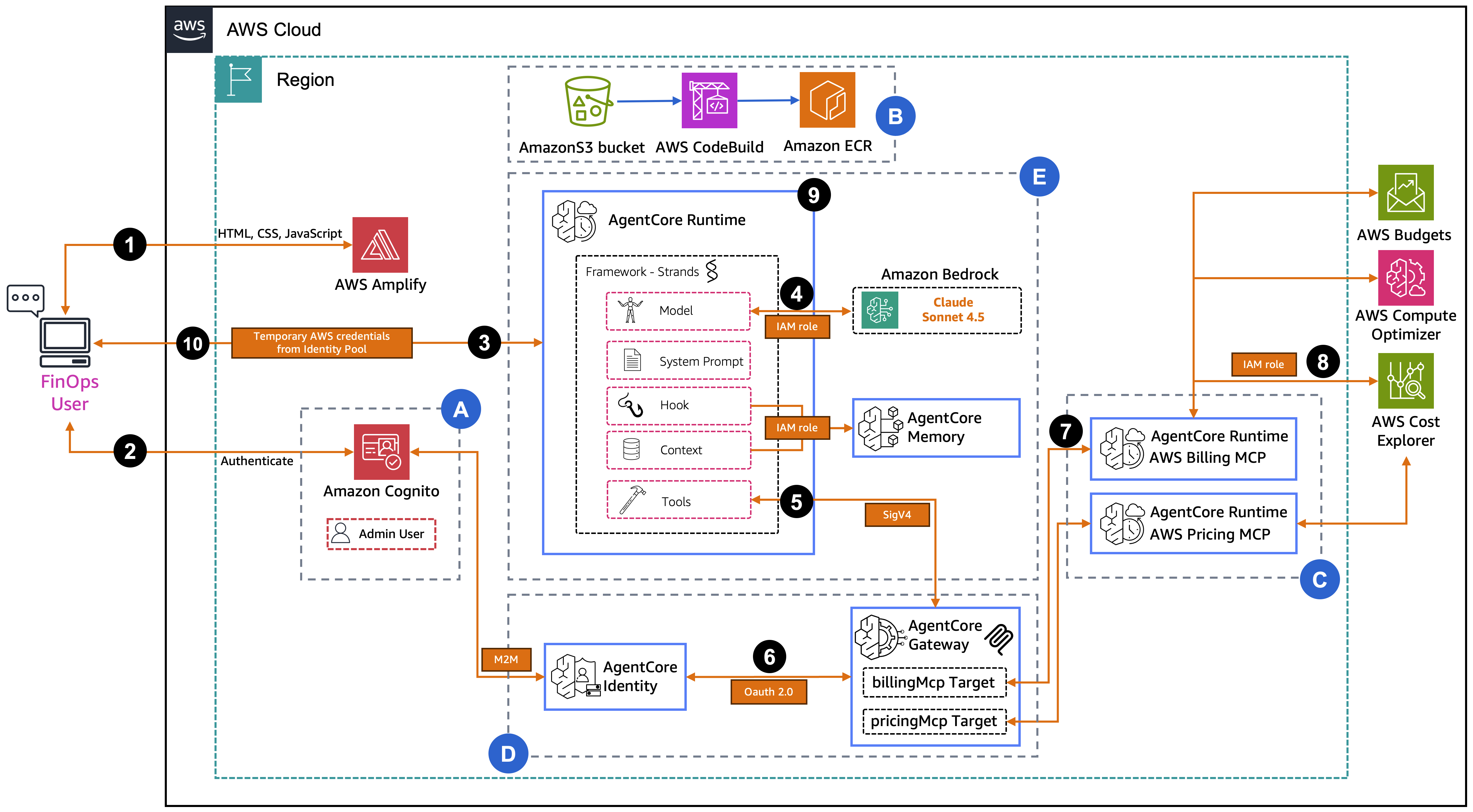
The following diagram illustrates the solution architecture.
The workflow consists of the following steps:
A developer pushes new code changes to their code repository (such as AWS CodeCommit), which automatically triggers the start of an AWS CodePipeline deployment.
The application code goes through a code building process, performs vulnerability scans, and conducts unit tests using your preferred tools.
AWS CodeBuild retrieves the repository and performs a git show command to extract the code differences between the current commit version and the previous commit version. This produces a line-by-line output that indicates the code changes made in this release.
CodeBuild saves the output to an Amazon DynamoDB table with additional reference information:
CodePipeline run ID
AWS Region
CodePipeline name
CodeBuild build number
Date and time
Status
Amazon DynamoDB Streams captures the data modifications made to the table.
An AWS Lambda function is triggered by the DynamoDB stream to process the record captured.
The function invokes the Anthropic Claude v2 model on Amazon Bedrock via the Amazon Bedrock InvokeModel API call. The code differences, together with a prompt, are provided as input to the model for analysis, and a summary of code changes is returned as output.
The output from the model is saved back to the same DynamoDB table.
The manager is notified via Amazon Simple Email Service (Amazon SES) of the summary of code changes and that their approval is required for the deployment.
The manager reviews the email and provides their decision (either approve or reject) together with any review comments via the CodePipeline console.
The approval decision and review comments are captured by Amazon EventBridge, which triggers a Lambda function to save them back to DynamoDB.
If approved, the pipeline deploys the application code using your preferred tools. If rejected, the workflow ends and the deployment does not proceed further.
In the following sections, you deploy the solution and verify the end-to-end workflow.
Prerequisites
To follow the instructions in this solution, you need the following prerequisites:
An AWS account with an AWS Identity and Access Management (IAM) user who has permissions to AWS CloudFormation, CodePipeline, CodeCommit, CodeBuild, DynamoDB, Lambda, Amazon Bedrock, Amazon SES, EventBridge, and IAM
Model access to Anthropic Claude on Amazon Bedrock
Deploy the solution
To deploy the solution, complete the following steps:
Choose Launch Stack to launch a CloudFormation stack in us-east-1:
For EmailAddress, enter an email address that you have access to. The summary of code changes will be sent to this email address.
For modelId, leave as the default anthropic.claude-v2, which is the Anthropic Claude v2 model.
Deploying the template will take about 4 minutes.
When you receive an email from Amazon SES to verify your email address, choose the link provided to authorize your email address.
You’ll receive an email titled “Summary of Changes” for the initial commit of the sample repository into CodeCommit.
On the AWS CloudFormation console, navigate to the Outputs tab of the deployed stack.
Copy the value of RepoCloneURL. You need this to access the sample code repository.
Test the solution
You can test the workflow end to end by taking on the role of a developer and pushing some code changes. A set of sample codes has been prepared for you in CodeCommit. To access the CodeCommit repository, enter the following commands on your IDE:
You will find the following directory structure for an AWS Cloud Development Kit (AWS CDK) application that creates a Lambda function to perform a bubble sort on a string of integers. The Lambda function is accessible via a publicly available URL.
You make three changes to the application codes.
To enhance the function to support both quick sort and bubble sort algorithm, take in a parameter to allow the selection of the algorithm to use, and return both the algorithm used and sorted array in the output, replace the entire content of lambda/index.py with the following code:
To reduce the timeout setting of the function from 10 minutes to 5 seconds (because we don’t expect the function to run longer than a few seconds), update line 47 in my_sample_project/my_sample_project_stack.py as follows:
To restrict the invocation of the function using IAM for added security, update line 56 in my_sample_project/my_sample_project_stack.py as follows:
Push the code changes by entering the following commands:
This starts the CodePipeline deployment workflow from Steps 1–9 as outlined in the solution overview. When invoking the Amazon Bedrock model, we provided the following prompt: