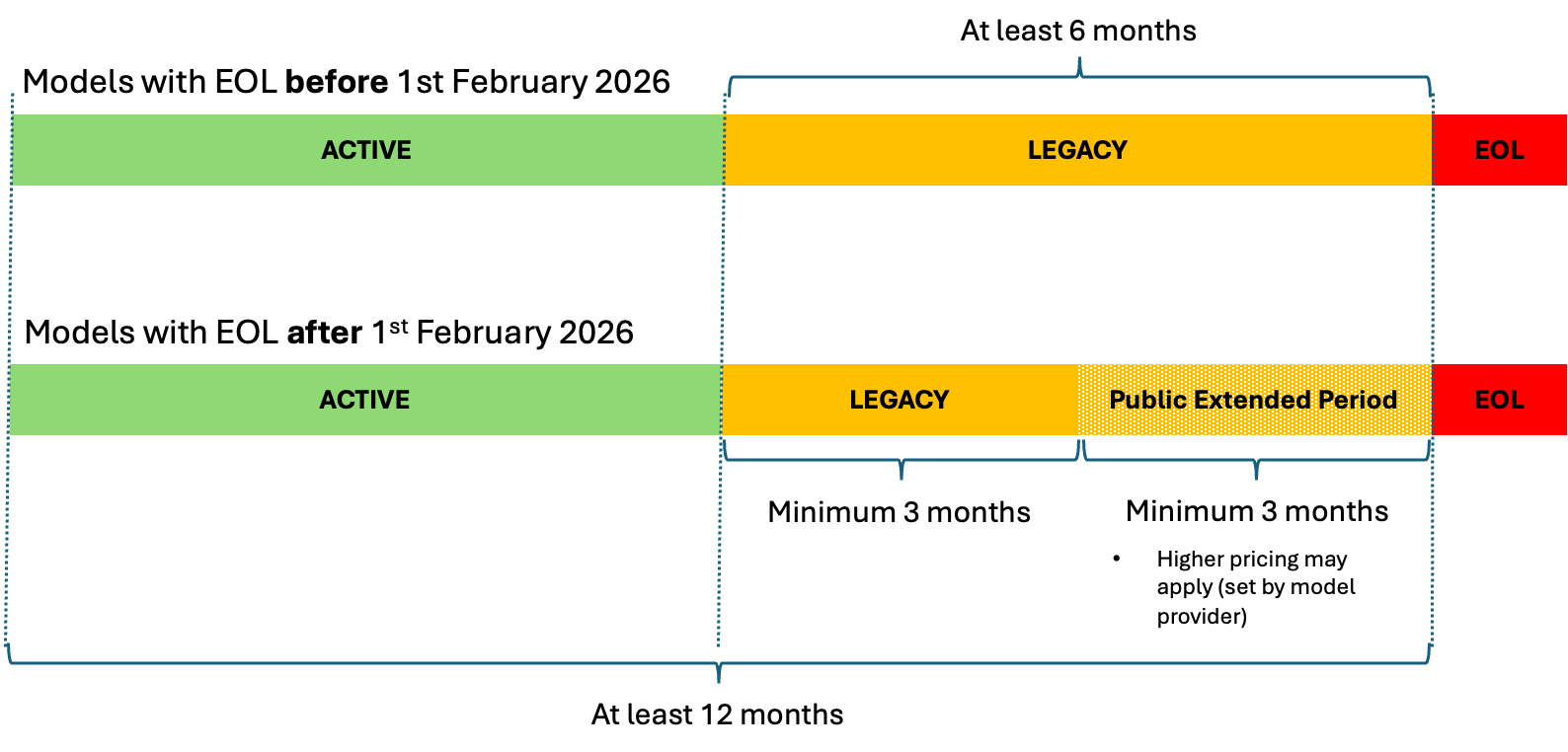
This is a guest post written by Axfood AB.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker.
Axfood is Sweden’s second largest food retailer, with over 13,000 employees and more than 300 stores. Axfood has a structure with multiple decentralized data science teams with different areas of responsibility. Together with a central data platform team, the data science teams bring innovation and digital transformation through AI and ML solutions to the organization. Axfood has been using Amazon SageMaker to cultivate their data using ML and has had models in production for many years. Lately, the level of sophistication and the sheer number of models in production is increasing exponentially. However, even though the pace of innovation is high, the different teams had developed their own ways of working and were in search of a new MLOps best practice.
Our challenge
To stay competitive in terms of cloud services and AI/ML, Axfood chose to partner with AWS and has been collaborating with them for many years.
During one of our recurring brainstorming sessions with AWS, we were discussing how to best collaborate across teams to increase the pace of innovation and efficiency of data science and ML practitioners. We decided to put in a joint effort to build a prototype on a best practice for MLOps. The aim of the prototype was to build a model template for all data science teams to build scalable and efficient ML models—the foundation to a new generation of AI and ML platforms for Axfood. The template should bridge and combine best practices from AWS ML experts and company-specific best practice models—the best of both worlds.
We decided to build a prototype from one of the currently most developed ML models within Axfood: forecasting sales in stores. More specifically, the forecast for fruits and vegetables of upcoming campaigns for food retail stores. Accurate daily forecasting supports the ordering process for the stores, increasing sustainability by minimizing food waste as a result of optimizing sales by accurately predicting the needed in-store stock levels. This was the perfect place to start for our prototype—not only would Axfood gain a new AI/ML platform, but we would also get a chance to benchmark our ML capabilities and learn from leading AWS experts.
Our solution: A new ML template on Amazon SageMaker Studio
Building a full ML pipeline that is designed for an actual business case can be challenging. In this case, we are developing a forecasting model, so there are two main steps to complete:
Train the model to make predictions using historical data.
Apply the trained model to make predictions of future events.
In Axfood’s case, a well-functioning pipeline for this purpose was already set up using SageMaker notebooks and orchestrated by the third-party workflow management platform Airflow. However, there are many clear benefits of modernizing our ML platform and moving to Amazon SageMaker Studio and Amazon SageMaker Pipelines. Moving to SageMaker Studio provides many predefined out-of-the-box features:
Monitoring model and data quality as well as model explainability
Built-in integrated development environment (IDE) tools such as debugging
Cost/performance monitoring
Model acceptance framework
Model registry
However, the most important incentive for Axfood is the ability to create custom project templates using Amazon SageMaker Projects to be used as a blueprint for all data science teams and ML practitioners. The Axfood team already had a robust and mature level of ML modeling, so the main focus was on building the new architecture.
Solution overview
Axfood’s proposed new ML framework is structured around two main pipelines: the model build pipeline and the batch inference pipeline:
These pipelines are versioned within two separate Git repositories: one build repository and one deploy (inference) repository. Together, they form a robust pipeline for forecasting fruits and vegetables.
The pipelines are packaged into a custom project template using SageMaker Projects in integration with a third-party Git repository (Bitbucket) and Bitbucket pipelines for continuous integration and continuous deployment (CI/CD) components.
The SageMaker project template includes seed code corresponding to each step of the build and deploy pipelines (we discuss these steps in more detail later in this post) as well as the pipeline definition—the recipe for how the steps should be run.
Automation of building new projects based on the template is streamlined through AWS Service Catalog, where a portfolio is created, serving as an abstraction for multiple products.
Each product translates into an AWS CloudFormation template, which is deployed when a data scientist creates a new SageMaker project with our MLOps blueprint as the foundation. This activates an AWS Lambda function that creates a Bitbucket project with two repositories—model build and model deploy—containing the seed code.
The following diagram illustrates the solution architecture. Workflow A depicts the intricate flow between the two model pipelines—build and inference. Workflow B shows the flow to create a new ML project.
Model build pipeline
The model build pipeline orchestrates the model’s lifecycle, beginning from preprocessing, moving through training, and culminating in being registered in the model registry:
Preprocessing – Here, the SageMaker ScriptProcessor class is employed for feature engineering, resulting in the dataset the model will be trained on.
Training and batch transform – Custom training and inference containers from SageMaker are harnessed to train the model on historical data and create predictions on the evaluation data using a SageMaker Estimator and Transformer for the respective tasks.
Evaluation – The trained model undergoes evaluation by comparing the generated predictions on the evaluation data to the ground truth using ScriptProcessor.
Baseline jobs – The pipeline creates baselines based on statistics in the input data. These are essential for monitoring data and model quality, as well as feature attributions.
Model registry – The trained model is registered for future use. The model will be approved by designated data scientists to deploy the model for use in production.
For production environments, data ingestion and trigger mechanisms are managed via a primary Airflow orchestration. Meanwhile, during development, the pipeline is activated each time a new commit is introduced to the model build Bitbucket repository. The following figure visualizes the model build pipeline.
Batch inference pipeline
The batch inference pipeline handles the inference phase, which consists of the following steps:
Preprocessing – Data is preprocessed using ScriptProcessor.
Batch transform – The model uses the custom inference container with a SageMaker Transformer and generates predictions given the input preprocessed data. The model used is the latest approved trained model in the model registry.
Postprocessing – The predictions undergo a series of postprocessing steps using ScriptProcessor.
Monitoring – Continuous surveillance completes checks for drifts related to data quality, model quality, and feature attribution.
If discrepancies arise, a business logic within the postprocessing script assesses whether retraining the model is necessary. The pipeline is scheduled to run at regular intervals.
The following diagram illustrates the batch inference pipeline. Workflow A corresponds to preprocessing, data quality and feature attribution drift checks, inference, and postprocessing. Workflow B corresponds to model quality drift checks. These pipelines are divided because the model quality drift check will only run if new ground truth data is available.
SageMaker Model Monitor
With Amazon SageMaker Model Monitor integrated, the pipelines benefit from real-time monitoring on the following:
Data quality – Monitors any drift or inconsistencies in data
Model quality – Watches for any fluctuations in model performance
Feature attribution – Checks for drift in feature attributions
Monitoring model quality requires access to ground truth data. Although obtaining ground truth can be challenging at times, using data or feature attribution drift monitoring serves as a competent proxy to model quality.
Specifically, in the case of data quality drift, the system watches out for the following:
Concept drift – This pertains to changes in the correlation between input and output, requiring ground truth
Covariate shift – Here, the emphasis is on alterations in the distribution of independent input variables
SageMaker Model Monitor’s data drift functionality meticulously captures and scrutinizes the input data, deploying rules and statistical checks. Alerts are raised whenever anomalies are detected.
In parallel to using data quality drift checks as a proxy for monitoring model degradation, the system also monitors feature attribution drift using the normalized discounted cumulative gain (NDCG) score. This score is sensitive to both changes in feature attribution ranking order as well as to the raw attribution scores of features. By monitoring drift in attribution for individual features and their relative importance, it’s straightforward to spot degradation in model quality.
Model explainability
Model explainability is a pivotal part of ML deployments, because it ensures transparency in predictions. For a detailed understanding, we use Amazon SageMaker Clarify.
It offers both global and local model explanations through a model-agnostic feature attribution technique based on the Shapley value concept. This is used to decode why a particular prediction was made during inference. Such explanations, which are inherently contrastive, can vary based on different baselines. SageMaker Clarify aids in determining this baseline using K-means or K-prototypes in the input dataset, which is then added to the model build pipeline. This functionality enables us to build generative AI applications in the future for increased understanding of how the model works.
Industrialization: From prototype to production
The MLOps project includes a high degree of automation and can serve as a blueprint for similar use cases:
The infrastructure can be reused entirely, whereas the seed code can be adapted for each task, with most changes limited to the pipeline definition and the business logic for preprocessing, training, inference, and postprocessing.
The training and inference scripts are hosted using SageMaker custom containers, so a variety of models can be accommodated without changes to the data and model monitoring or model explainability steps, as long as the data is in tabular format.
After finishing the work on the prototype, we turned to how we should use it in production. To do so, we felt the need to make some additional adjustments to the MLOps template:
The original seed code used in the prototype for the template included preprocessing and postprocessing steps run before and after the core ML steps (training and inference). However, when scaling up to use the template for multiple use cases in production, the built-in preprocessing and postprocessing steps may lead to decreased generality and reproduction of code.
To improve generality and minimize repetitive code, we chose to slim down the pipelines even further. Instead of running the preprocessing and postprocessing steps as part of the ML pipeline, we run these as part of the primary Airflow orchestration before and after triggering the ML pipeline.
This way, use case-specific processing tasks are abstracted from the template, and what is left is a core ML pipeline performing tasks that are general across multiple use cases with minimal repetition of code. Parameters that differ between use cases are supplied as input to the ML pipeline from the primary Airflow orchestration.
The result: A rapid & efficient approach to model build & deployment
The prototype in collaboration with AWS has resulted in an MLOps template following current best practices that is now available for use to all of Axfood’s data science teams. By creating a new SageMaker project within SageMaker Studio, data scientists can get started on new ML projects quickly and seamlessly transition to production, allowing for more efficient time management. This is made possible by automating tedious, repetitive MLOps tasks as part of the template.
Furthermore, several new functionalities have been added in an automated fashion to our ML setup. These gains include:
Model monitoring – We can perform drift checks for model and data quality as well as model explainability
Model and data lineage – It’s now possible to trace exactly which data has been used for which model
Model registry – This helps us catalog models for production and manage model versions
Conclusion
In this post, we discussed how Axfood improved operations and scalability of our existing AI and ML operations in collaboration with AWS experts and by using SageMaker and its related products.
These improvements will help Axfood’s data science teams building ML workflows in a more standardized way and will greatly simplify analysis and monitoring of models in production—ensuring the quality of ML models built and maintained by our teams.
Please leave any feedback or questions in the comments section.
About the Authors
Dr. Björn Blomqvist is the Head of AI Strategy at Axfood AB. Before joining Axfood AB he led a team of Data Scientists at Dagab, a part of Axfood, building innovative machine learning solutions with the mission to provide good and sustainable food to people all over Sweden. Born and raised in the north of Sweden, in his spare time Björn ventures to snowy mountains and open seas.
Oskar Klang is a Senior Data Scientist at the analytics department at Dagab, where he enjoys working with everything analytics and machine learning, e.g. optimizing supply chain operations, building forecasting models and, more recently, GenAI applications. He is committed to building more streamlined machine learning pipelines, enhancing efficiency and scalability.
Pavel Maslov is a Senior DevOps and ML engineer in the Analytic Platforms team. Pavel has extensive experience in the development of frameworks, infrastructure, and tools in the domains of DevOps and ML/AI on the AWS platform. Pavel has been one of the key players in building the foundational capability within ML at Axfood.
Joakim Berg is the Team Lead and Product Owner Analytic Platforms, based in Stockholm Sweden. He is leading a team of Data Platform end DevOps/MLOps engineers providing Data and ML platforms for the Data Science teams. Joakim has many years of experience leading senior development and architecture teams from different industries.