Generative AI agents are capable of producing human-like responses and engaging in natural language conversations by orchestrating a chain of calls to foundation models (FMs) and other augmenting tools based on user input. Instead of only fulfilling predefined intents through a static decision tree, agents are autonomous within the context of their suite of available tools. Amazon Bedrock is a fully managed service that makes leading FMs from AI companies available through an API along with developer tooling to help build and scale generative AI applications.
In this post, we demonstrate how to build a generative AI financial services agent powered by Amazon Bedrock. The agent can assist users with finding their account information, completing a loan application, or answering natural language questions while also citing sources for the provided answers. This solution is intended to act as a launchpad for developers to create their own personalized conversational agents for various applications, such as virtual workers and customer support systems. Solution code and deployment assets can be found in the GitHub repository.
Amazon Lex supplies the natural language understanding (NLU) and natural language processing (NLP) interface for the open source LangChain conversational agent embedded within an AWS Amplify website. The agent is equipped with tools that include an Anthropic Claude 2.1 FM hosted on Amazon Bedrock and synthetic customer data stored on Amazon DynamoDB and Amazon Kendra to deliver the following capabilities:
Provide personalized responses – Query DynamoDB for customer account information, such as mortgage summary details, due balance, and next payment date
Access general knowledge – Harness the agent’s reasoning logic in tandem with the vast amounts of data used to pre-train the different FMs provided through Amazon Bedrock to produce replies for any customer prompt
Curate opinionated answers – Inform agent responses using an Amazon Kendra index configured with authoritative data sources: customer documents stored in Amazon Simple Storage Service (Amazon S3) and Amazon Kendra Web Crawler configured for the customer’s website
Solution overview
Demo recording
The following demo recording highlights agent functionality and technical implementation details.
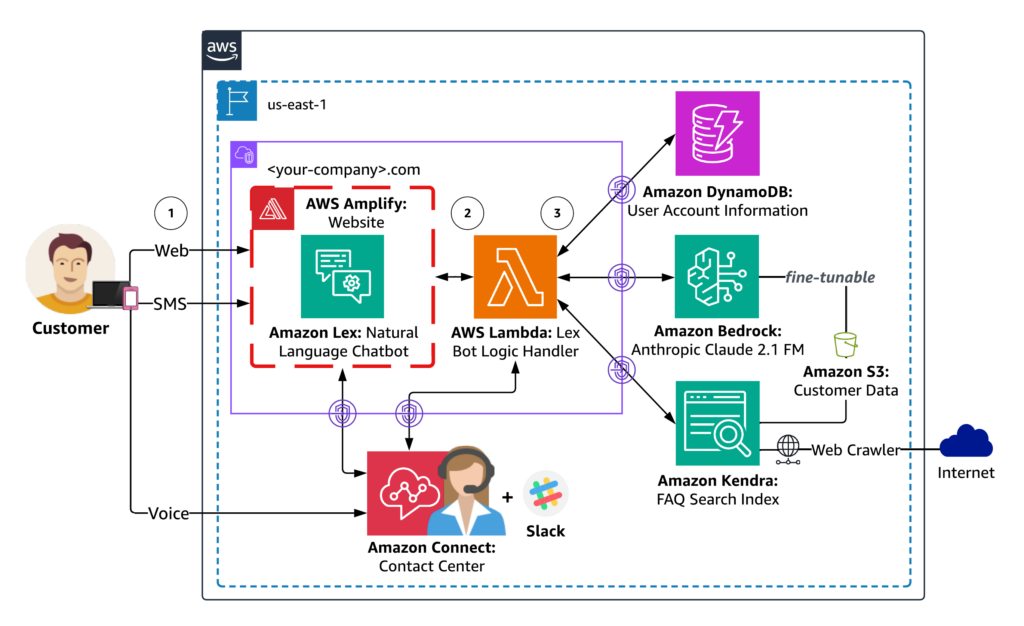
Solution architecture
The following diagram illustrates the solution architecture.
The agent’s response workflow includes the following steps:
Users perform natural language dialog with the agent through their choice of web, SMS, or voice channels. The web channel includes an Amplify hosted website with an Amazon Lex embedded chatbot for a fictitious customer. SMS and voice channels can be optionally configured using Amazon Connect and messaging integrations for Amazon Lex. Each user request is processed by Amazon Lex to determine user intent through a process called intent recognition, which involves analyzing and interpreting the user’s input (text or speech) to understand the user’s intended action or purpose.
Amazon Lex then invokes an AWS Lambda handler for user intent fulfillment. The Lambda function associated with the Amazon Lex chatbot contains the logic and business rules required to process the user’s intent. Lambda performs specific actions or retrieves information based on the user’s input, making decisions and generating appropriate responses.
Lambda instruments the financial services agent logic as a LangChain conversational agent that can access customer-specific data stored on DynamoDB, curate opinionated responses using your documents and webpages indexed by Amazon Kendra, and provide general knowledge answers through the FM on Amazon Bedrock. Responses generated by Amazon Kendra include source attribution, demonstrating how you can provide additional contextual information to the agent through Retrieval Augmented Generation (RAG). RAG allows you to enhance your agent’s ability to generate more accurate and contextually relevant responses using your own data.
Agent architecture
The following diagram illustrates the agent architecture.
The agent’s reasoning workflow includes the following steps:
The LangChain conversational agent incorporates conversation memory so it can respond to multiple queries with contextual generation. This memory allows the agent to provide responses that take into account the context of the ongoing conversation. This is achieved through contextual generation, where the agent generates responses that are relevant and contextually appropriate based on the information it has remembered from the conversation. In simpler terms, the agent remembers what was said earlier and uses that information to respond to multiple questions in a way that makes sense in the ongoing discussion. Our agent uses LangChain’s DynamoDB chat message history class as a conversation memory buffer so it can recall past interactions and enhance the user experience with more meaningful, context-aware responses.
The agent uses Anthropic Claude 2.1 on Amazon Bedrock to complete the desired task through a series of carefully self-generated text inputs known as prompts. The primary objective of prompt engineering is to elicit specific and accurate responses from the FM. Different prompt engineering techniques include:
Zero-shot – A single question is presented to the model without any additional clues. The model is expected to generate a response based solely on the given question.
Few-shot – A set of sample questions and their corresponding answers are included before the actual question. By exposing the model to these examples, it learns to respond in a similar manner.
Chain-of-thought – A specific style of few-shot prompting where the prompt is designed to contain a series of intermediate reasoning steps, guiding the model through a logical thought process, ultimately leading to the desired answer.
Our agent utilizes chain-of-thought reasoning by running a set of actions upon receiving a request. Following each action, the agent enters the observation step, where it expresses a thought. If a final answer is not yet achieved, the agent iterates, selecting different actions to progress towards reaching the final answer. See the following example code:
Action: The action to take
Action Input: The input to the action
Observation: The result of the action
FSI Agent: [answer and source documents]
As part of the agent’s different reasoning paths and self-evaluating choices to decide the next course of action, it has the ability to access synthetic customer data sources through an Amazon Kendra Index Retriever tool. Using Amazon Kendra, the agent performs contextual search across a wide range of content types, including documents, FAQs, knowledge bases, manuals, and websites. For more details on supported data sources, refer to Data sources. The agent has the power to use this tool to provide opinionated responses to user prompts that should be answered using an authoritative, customer-provided knowledge library, instead of the more general knowledge corpus used to pretrain the Amazon Bedrock FM.
Deployment guide
In the following sections, we discuss the key steps to deploy the solution, including pre-deployment and post-deployment.
Pre-deployment
Before you deploy the solution, you need to create your own forked version of the solution repository with a token-secured webhook to automate continuous deployment of your Amplify website. The Amplify configuration points to a GitHub source repository from which our website’s frontend is built.
Fork and clone generative-ai-amazon-bedrock-langchain-agent-example repository
To control the source code that builds your Amplify website, follow the instructions in Fork a repository to fork the generative-ai-amazon-bedrock-langchain-agent-example repository. This creates a copy of the repository that is disconnected from the original code base, so you can make the appropriate modifications.
Please note of your forked repository URL to use to clone the repository in the next step and to configure the GITHUB_PAT environment variable used in the solution deployment automation script.
Clone your forked repository using the git clone command:
Create a GitHub personal access token
The Amplify hosted website uses a GitHub personal access token (PAT) as the OAuth token for third-party source control. The OAuth token is used to create a webhook and a read-only deploy key using SSH cloning.
To create your PAT, follow the instructions in Creating a personal access token (classic). You may prefer to use a GitHub app to access resources on behalf of an organization or for long-lived integrations.
Take note of your PAT before closing your browser—you will use it to configure the GITHUB_PAT environment variable used in the solution deployment automation script. The script will publish your PAT to AWS Secrets Manager using AWS Command Line Interface (AWS CLI) commands and the secret name will be used as the GitHubTokenSecretName AWS CloudFormation parameter.
Deployment
The solution deployment automation script uses the parameterized CloudFormation template, GenAI-FSI-Agent.yml, to automate provisioning of following solution resources:
An Amplify website to simulate your front-end environment.
An Amazon Lex bot configured through a bot import deployment package.
Four DynamoDB tables:
UserPendingAccountsTable – Records pending transactions (for example, loan applications).
UserExistingAccountsTable – Contains user account information (for example, mortgage account summary).
ConversationIndexTable – Tracks the conversation state.
ConversationTable – Stores conversation history.
An S3 bucket that contains the Lambda agent handler, Lambda data loader, and Amazon Lex deployment packages, along with customer FAQ and mortgage application example documents.
Two Lambda functions:
Agent handler – Contains the LangChain conversational agent logic that can intelligently employ a variety of tools based on user input.
Data loader – Loads example customer account data into UserExistingAccountsTable and is invoked as a custom CloudFormation resource during stack creation.
A Lambda layer for Amazon Bedrock Boto3, LangChain, and pdfrw libraries. The layer supplies LangChain’s FM library with an Amazon Bedrock model as the underlying FM and provides pdfrw as an open source PDF library for creating and modifying PDF files.
An Amazon Kendra index that provides a searchable index of customer authoritative information, including documents, FAQs, knowledge bases, manuals, websites, and more.
Two Amazon Kendra data sources:
Amazon S3 – Hosts an example customer FAQ document.
Amazon Kendra Web Crawler – Configured with a root domain that emulates the customer-specific website (for example, <your-company>.com).
AWS Identity and Access Management (IAM) permissions for the preceding resources.
AWS CloudFormation prepopulates stack parameters with the default values provided in the template. To provide alternative input values, you can specify parameters as environment variables that are referenced in the `ParameterKey=<ParameterKey>,ParameterValue=<Value>` pairs in the following shell script’s `aws cloudformation create-stack` command.
Before you run the shell script, navigate to your forked version of the generative-ai-amazon-bedrock-langchain-agent-example repository as your working directory and modify the shell script permissions to executable:
Set your Amplify repository and GitHub PAT environment variables created during the pre-deployment steps:
Finally, run the solution deployment automation script to deploy the solution’s resources, including the GenAI-FSI-Agent.yml CloudFormation stack:
source ./create-stack.sh
Solution Deployment Automation Script
The preceding source ./create-stack.sh shell command runs the following AWS CLI commands to deploy the solution stack:
Post-deployment
In this section, we discuss the post-deployment steps for launching a frontend application that is intended to emulate the customer’s Production application. The financial services agent will operate as an embedded assistant within the example web UI.
Launch a web UI for your chatbot
The Amazon Lex web UI, also known as the chatbot UI, allows you to quickly provision a comprehensive web client for Amazon Lex chatbots. The UI integrates with Amazon Lex to produce a JavaScript plugin that will incorporate an Amazon Lex-powered chat widget into your existing web application. In this case, we use the web UI to emulate an existing customer web application with an embedded Amazon Lex chatbot. Complete the following steps:
Follow the instructions to deploy the Amazon Lex web UI CloudFormation stack.
On the AWS CloudFormation console, navigate to the stack’s Outputs tab and locate the value for SnippetUrl.
Copy the web UI Iframe snippet, which will resemble the format under Adding the ChatBot UI to your Website as an Iframe.
Edit your forked version of the Amplify GitHub source repository by adding your web UI JavaScript plugin to the section labeled <– Paste your Lex Web UI JavaScript plugin here –> for each of the HTML files under the front-end directory: index.html, contact.html, and about.html.
Amplify provides an automated build and release pipeline that triggers based on new commits to your forked repository and publishes the new version of your website to your Amplify domain. You can view the deployment status on the Amplify console.
Access the Amplify website
With your Amazon Lex web UI JavaScript plugin in place, you are now ready to launch your Amplify demo website.
To access your website’s domain, navigate to the CloudFormation stack’s Outputs tab and locate the Amplify domain URL. Alternatively, use the following command:
After you access your Amplify domain URL, you can proceed with testing and validation.
Testing and validation
The following testing procedure aims to verify that the agent correctly identifies and understands user intents for accessing customer data (such as account information), fulfilling business workflows through predefined intents (such as completing a loan application), and answering general queries, such as the following sample prompts:
Why should I use <your-company>?
How competitive are their rates?
Which type of mortgage should I use?
What are current mortgage trends?
How much do I need saved for a down payment?
What other costs will I pay at closing?
Response accuracy is determined by evaluating the relevancy, coherency, and human-like nature of the answers generated by the Amazon Bedrock provided Anthropic Claude 2.1 FM. The source links provided with each response (for example, <your-company>.com based on the Amazon Kendra Web Crawler configuration) should also be confirmed as credible.
Provide personalized responses
Verify the agent successfully accesses and utilizes relevant customer information in DynamoDB to tailor user-specific responses.
Note that the use of PIN authentication within the agent is for demonstration purposes only and should not be used in any production implementation.
Curate opinionated answers
Validate that opinionated questions are met with credible answers by the agent correctly sourcing replies based on authoritative customer documents and webpages indexed by Amazon Kendra.
Deliver contextual generation
Determine the agent’s ability to provide contextually relevant responses based on previous chat history.
Access general knowledge
Confirm the agent’s access to general knowledge information for non-customer-specific, non-opinionated queries that require accurate and coherent responses based on Amazon Bedrock FM training data and RAG.
Run predefined intents
Ensure the agent correctly interprets and conversationally fulfills user prompts that are intended to be routed to predefined intents, such as completing a loan application as part of a business workflow.
The following is the resultant loan application document completed through the conversational flow.
The multi-channel support functionality can be tested in conjunction with the preceding assessment measures across web, SMS, and voice channels. For more information about integrating the chatbot with other services, refer to Integrating an Amazon Lex V2 bot with Twilio SMS and Add an Amazon Lex bot to Amazon Connect.
Clean up
To avoid charges in your AWS account, clean up the solution’s provisioned resources.
Revoke the GitHub personal access token. GitHub PATs are configured with an expiration value. If you want to ensure that your PAT can’t be used for programmatic access to your forked Amplify GitHub repository before it reaches its expiry, you can revoke the PAT by following the GitHub repo’s instructions.
Delete the GenAI-FSI-Agent.yml CloudFormation stack and other solution resources using the solution deletion automation script. The following commands use the default stack name. If you customized the stack name, adjust the commands accordingly.# export STACK_NAME=<YOUR-STACK-NAME>
./delete-stack.sh
Solution Deletion Automation Script
The delete-stack.sh shell script deletes the resources that were originally provisioned using the solution deployment automation script, including the GenAI-FSI-Agent.yml CloudFormation stack.
Considerations
Although the solution in this post showcases the capabilities of a generative AI financial services agent powered by Amazon Bedrock, it is essential to recognize that this solution is not production-ready. Rather, it serves as an illustrative example for developers aiming to create personalized conversational agents for diverse applications like virtual workers and customer support systems. A developer’s path to production would iterate on this sample solution with the following considerations.
Security and privacy
Ensure data security and user privacy throughout the implementation process. Implement appropriate access controls and encryption mechanisms to protect sensitive information. Solutions like the generative AI financial services agent will benefit from data that isn’t yet available to the underlying FM, which often means you will want to use your own private data for the biggest jump in capability. Consider the following best practices:
Keep it secret, keep it safe – You will want this data to stay completely protected, secure, and private during the generative process, and want control over how this data is shared and used.
Establish usage guardrails – Understand how data is used by a service before making it available to your teams. Create and distribute the rules for what data can be used with what service. Make these clear to your teams so they can move quickly and prototype safely.
Involve Legal, sooner rather than later – Have your Legal teams review the terms and conditions and service cards of the services you plan to use before you start running any sensitive data through them. Your Legal partners have never been more important than they are today.
As an example of how we are thinking about this at AWS with Amazon Bedrock: All data is encrypted and does not leave your VPC, and Amazon Bedrock makes a separate copy of the base FM that is accessible only to the customer, and fine tunes or trains this private copy of the model.
User acceptance testing
Conduct user acceptance testing (UAT) with real users to evaluate the performance, usability, and satisfaction of the generative AI financial services agent. Gather feedback and make necessary improvements based on user input.
Deployment and monitoring
Deploy the fully tested agent on AWS, and implement monitoring and logging to track its performance, identify issues, and optimize the system as needed. Lambda monitoring and troubleshooting features are enabled by default for the agent’s Lambda handler.
Maintenance and updates
Regularly update the agent with the latest FM versions and data to enhance its accuracy and effectiveness. Monitor customer-specific data in DynamoDB and synchronize your Amazon Kendra data source indexing as needed.
Conclusion
In this post, we delved into the exciting world of generative AI agents and their ability to facilitate human-like interactions through the orchestration of calls to FMs and other complementary tools. By following this guide, you can use Bedrock, LangChain, and existing customer resources to successfully implement, test, and validate a reliable agent that provides users with accurate and personalized financial assistance through natural language conversations.
In an upcoming post, we will demonstrate how the same functionality can be delivered using an alternative approach with Agents for Amazon Bedrock and Knowledge base for Amazon Bedrock. This fully AWS-managed implementation will further explore how to offer intelligent automation and data search capabilities through personalized agents that transform the way users interact with your applications, making interactions more natural, efficient, and effective.
About the author
Kyle T. Blocksom is a Sr. Solutions Architect with AWS based in Southern California. Kyle’s passion is to bring people together and leverage technology to deliver solutions that customers love. Outside of work, he enjoys surfing, eating, wrestling with his dog, and spoiling his niece and nephew.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}